
Word2Vec
이번 포스팅에서 다룰 내용은 Word embedding 기술중 하나인 Word2Vec이다.
One-hot encoding
Neural network은 커다란 계산식과 같기 때문에 그 입력 값은 항상 숫자가 되어야 한다.
그렇기 때문에 neural network에 자연어를 입력으로 주기 위해서는 자연어를 숫자로 바꿔줄 필요가 있다.
그 중에서 가장 단순하고 쉬운 방법이 one-hot encoding이라고 할 수 있다.
One-hot encoding을 사용하면 사전에 존재하는 단어 수 만큼의 zero vector를 만들고 각 단어들마다 vector의 특정 위치의 값을 1로 바꿔 그 단어를 숫자로 표현할 수 있다.
예를 들면, 사전에 “apple”, “banana”, “cat”, “dog”, “ear” 5개의 단어가 있다고 하면 각각
\[[1 0 0 0 0], [0 1 0 0 0], [0 0 1 0 0], [0 0 0 1 0], [0 0 0 0 1]\]로 표현할 수 있다.
이렇게 하면 모든 단어들이 구분되도록 숫자로 표현할 수 있다.
Word embedding
One-hot encoding의 단점은 vector의 크기가 너무 커진다는 것이다.
단어 사전의 크기가 5만 이라고 하면 neural network에 하나의 문장을 입력할 때 문장의 각 단어마다 크기가 5만인 vector가 필요하고 이것은 많은 연산을 필요로 한다.
또한, one-hot encoding으로 모든 단어를 구별할 수는 있지만 각 단어들간 관계는 표현할 수 없다.
이러한 단점을 보완하기 위해 사용하는 것이 word embedding이다.
‘Encoding’이 아닌 ‘Embedding’이라는 단어를 사용하는 이유는 단순하게 구분되도록 숫자로 표현하는 것이 아니라 단어들의 관계를 최대한 유지하면서 숫자로 표현하기 때문이다.
Word2Vec
Word2Vec은 대표적인 word embedding 모델이다.
Word2Vec의 특징은 단어간 연산이 가능하다는 것이다.
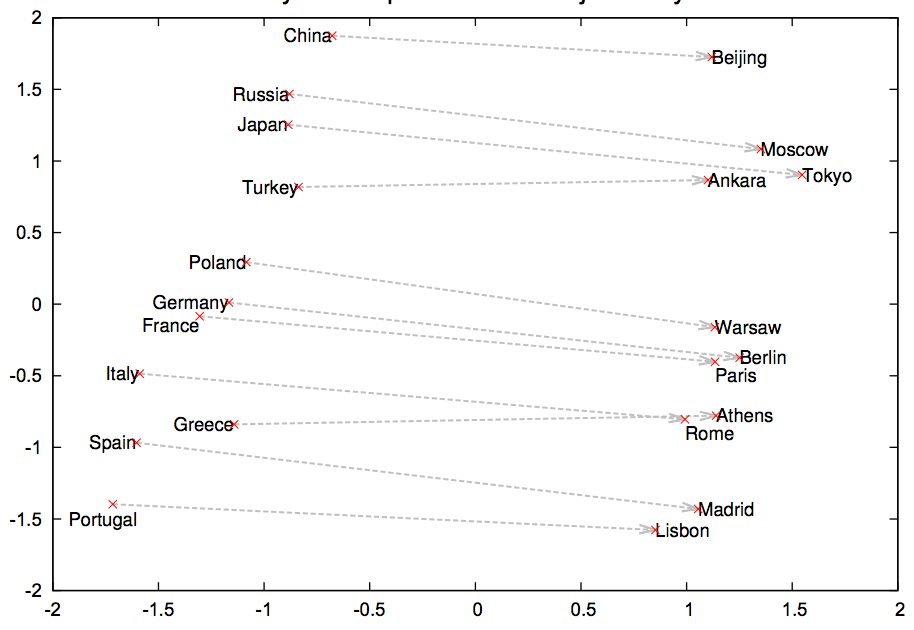
예를 들면, Japan - Tokyo + Paris = France 처럼 국가(Japan)를 표현하는 vector에서 그 국가의 수도(Tokyo)를 표현하는 vector를 빼고 또 다른 국가의 수도(Paris)를 표현하는 vector를 더하면 새로운 국가(France)를 표현하는 vector를 얻을 수 있다.
여기서 확인할 수 있는 것은 Word2Vec 모델이 국가와 수도간의 관계를 학습할 수 있다는 것이다.
Word2Vec을 사용해 단어들을 vector로 표현한 후에 차원 축소 알고리즘(t_SNE, PCA 등)을 사용해 2차원으로 축소하면 아래와 같이 단어들의 분포를 확인할 수 있다.
아래와 같이 embedding matrix를 구하면 one-hot encoding한 vector를 그대로 사용하지 않고 embedding된 vector를 neural network의 입력으로 사용할 수 있다.
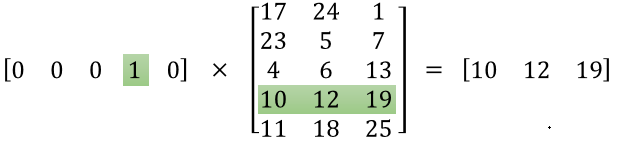
Word2Vec의 목적은 학습을 통해 위와 같은 embedding matrix를 찾는 것이다.
Skip-gram
Word2Vec을 학습하는 방법은 Skip-gram 방식과 CBOW(Continuous Bag Of Words) 방식이 있지만 Skip-gram 방식이 더 알려져 있고 잘 사용된다.
Skip-gram은 먼저 window size를 설정한 후에 문장의 단어들을 순회하며 각각의 단어들을 중심으로 잡았을 때 window size안에 포함된 단어들을 예측하도록 학습하는 방식이다.
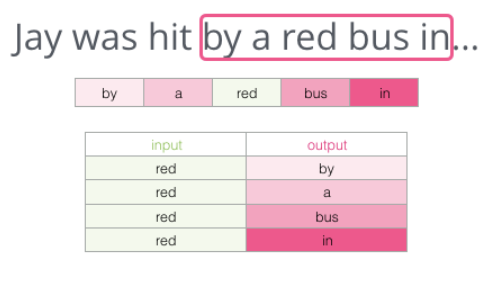
위와 같이 “by a red bus in” 이라는 sequence에서 총 4개의 학습 데이터를 만들어 낼 수 있다.
같은 방법으로 window를 움직이며 문장의 모든 단어에 대해 데이터를 만들고 Word2Vec 모델을 학습시킨다.
직관적으로 생각하면 Word2Vec은 한 문장내에 자주 같이 나오는 단어들을 파악해 그 단어들의 관계를 학습한다고 할 수 있다.
하지만 기본적으로 이 학습 방법은 softmax를 사용해 단어를 예측하기 때문에 단어 사전의 크기가 커질수록 softmax를 수행할 때 연산의 비용이 커진다.
이러한 점을 보완하기 위해 Negative sampling이라는 방법을 사용하기도 한다.
Negative sampling
기본적으로 중심 단어에 대해서 window안에 같이 등장하는 단어를 positive sample로 만드는 것은 skip-gram과 동일하다.
하지만 여기서 추가로, window안에 등장하지 않는 단어들을 무작위로 골라 negative sample을 만든다.
Positive sample과 negative sample을 추출한 후에 중심 단어를 입력 받았을 때 positive sample의 단어들을 예측하도록 모델을 학습시키는데, 이 때 softmax를 전체 단어 사전에 대해서 적용하는 것이 아니라 positive sample과 negative sample을 합쳐서 새로운 작은 사전을 만든 후에 그 사전에 대해서만 적용한다.
예를 들어, 전체 단어 사전의 크기가 3만, window size가 2일 때(양쪽으로 2단어) “The quick brown fox jumps”라는 문장을 학습시킨다고 해보자. 중심 단어가 “brown” 일 때, 먼저 positive sample은
\[(brown, the), (brown, quick), (brown, fox), (brown, jumps)\]과 같이 만들 수 있다.
다음으로 negative sample은 단어 사전에서 window에 등장하지 않는 단어들을 무작위로 5개 골라 다음과 같이 추출한다. (실제로는 5개가 아니고 더 많이 추출함)
\[(brown, apple), (brown, banana), (brown, man), (brown, paper), (brown, pig)\]이렇게 총 9개의 데이터를 만들었다. 이제 Word2Vec 모델을 학습시키는데, softmax를 3만개의 단어가 아닌 10개(9개+brown)의 단어에 대해서 계산한다.
사전의 모든 단어를 사용하는 것보다 정확성은 조금 떨어질 수 있지만 negative sample 수를 잘 조절하면 효율성을 높일 수 있다.
Leave a comment