
한국어 감정 분석
1. 개발 도구
- Python 3
- Tensorflow
- gensim
- konlpy
2. 데이터
네이버에서 제공한 Naver sentiment movie corpus 데이터를 사용 (데이터 제공)
15만건의 학습 데이터를 사용해 모델을 학습하고 5만건의 테스트 데이터로 모델의 성능을 검증

3. 전처리
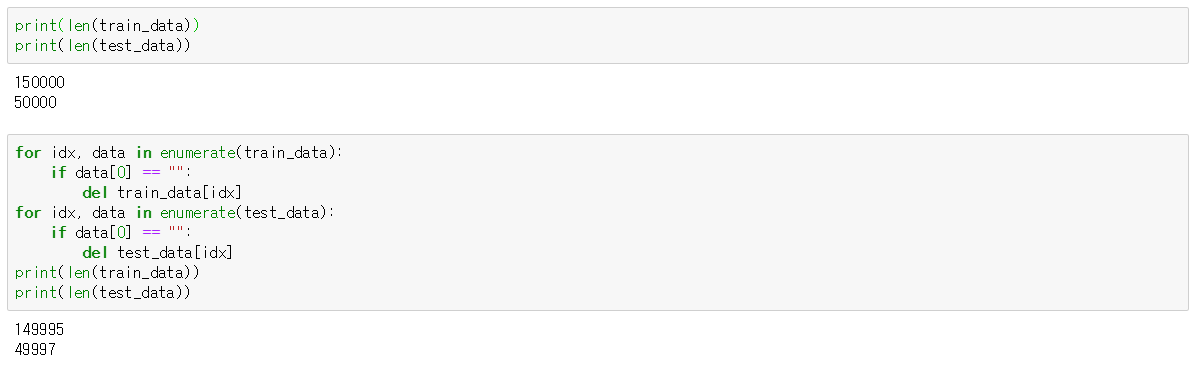
Null 데이터 제거
몇개의 데이터가 빈 문장(““)으로 이루어진 것을 확인했고 해당 데이터들을 제거
토큰화
konlpy에서 제공하는 형태소 분석기 Okt를 사용해 각 문장들을 단어로 나누고 품사 태깅

품사 태깅이 완료된 단어들을 “단어/품사” 형태로 토큰화

임베딩
gensim에서 제공하는 Word2Vec 모델을 사용해 단어들을 벡터로 임베딩
토큰화된 데이터들로 Word2Vec에 사용할 사전을 생성하고 학습
Word2Vec 모델을 통해 단어 토큰을 크기가 300인 벡터로 임베딩

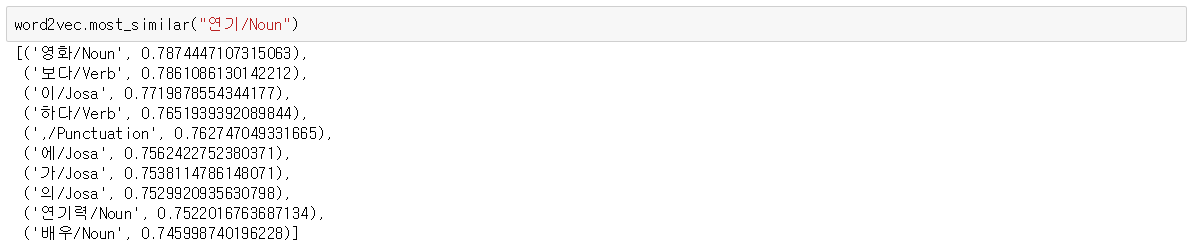
사전에 없는 단어는 임베딩 벡터와 같은 크기로 랜덤한 벡터로 변환

4. 딥러닝 모델
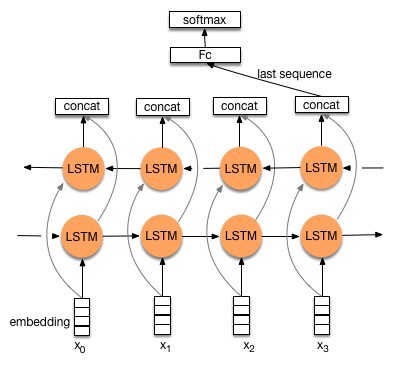
Bidirectional LSTM
딥러닝 모델은 tensorflow에서 제공하는 bidirectional LSTM을 사용
모델 학습 & 검증
모델의 layer 수는 1, LSTM cell의 hidden unit 수는 128, LSTM의 최대 length는 100으로 지정
batch size는 32, dropout은 0.75, learning rate는 0.001, epochs는 3으로 모델을 학습
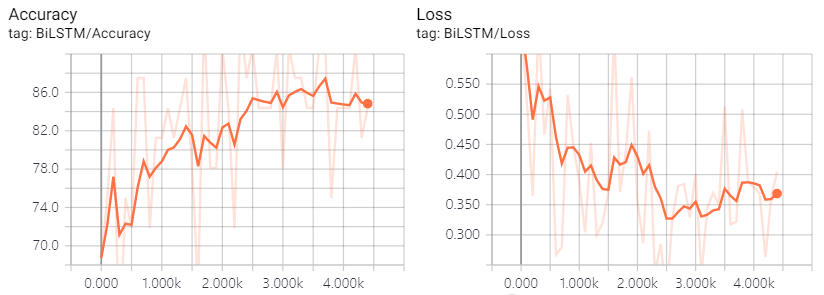
모델 학습 후, 5만건의 테스트 데이터에 대해 검증해본 결과 약 83%의 정확도를 기록
5. 결과
문장 테스트
직접 한국어 문장을 입력해 긍정 리뷰일 확률을 출력해 모델이 실제로 잘 작동하는지 확인

모델을 튜닝하지 않았음에도 어느정도 잘 작동하는 것을 확인
모델의 파라미터를 튜닝하면 모델의 성능을 더 올릴 수 있을 것으로 보임
Leave a comment