
Pooled Contextualized Embeddings for Named Entity Recognition
Word embedding은 단어들의 latent semantic을 표현하는 방법이며, NLP에 있어 중요한 기술이다.
최근의 word embedding은 문맥 정보를 사용하여, 같은 단어라도 문맥에 따라 다른 embedding을 만드는 방법을 사용한다.
본 연구는 Contextual String Embeddings for Sequence Labeling의 후속 연구이다.
이전 연구의 단점을 개선하고, 역시 NER이나 POS tagging 같은 sequence labeling에 적용하여 좋은 결과를 얻었다.
이전 연구의 방법은 설명되지 않은 문맥상에서 희귀한 단어가 등장했을 때, 제대로 처리하지 못하는 문제가 존재한다.
예를들어, Fung Permadi v Indra라는 문장에서 Indra라는 단어는 희귀한 단어이며, 문맥상으로도 유추하기 힘든 단어이다.
Pooled Contextual Embeddings
이전 연구의 단점을 보완하기 위해 간단하지만 효율적인 방법을 제안한다.
본 연구는 위의 예시의 Indra 같은 단어들은 이전 문장들에서 미리 좀 더 분명하게 설명되고, 문장에 등장할 것이라는 직관에서 시작된다.
실제로, Fung Permadi v Indra 라는 문장은 CoNLL-03 data에 있던 문장이며, Indra는 이전 문장인 Indra Wijaya beat Ong Ewe Hock 라는 문장에서 먼저 등장한다.
본 연구에서 제안하는 방법은 이전 문장들의 문맥 정보를 얻기 위해 메모리를 사용한다.
어떤 단어를 embedding할 때, 그 문장의 embedding만 사용하는 것이 아니라, 그 단어가 등장했던 이전 문장들에서 만들어진 embedding을 같이 사용한다.
즉, 메모리에서 같은 단어의 embedding 정보들을 불러와서 pooling을 적용한 뒤에, 현재 문장에서 얻은 embedding과 concat해서 사용한다.
위의 예시를 설명하면, Fung Permadi v Indra에서 먼저 Indra의 embedding을 구하고, 메모리에 저장되어 있는 Indra Wijaya beat Ong Ewe Hock에서 얻은 Indra의 embedding을 가져온다.
만약 Indra가 먼저 등장했던 문장들이 더 있다면, pooling을 적용한 뒤에 Fung Permadi v Indra에서 구한 Indra의 embedding과 concat을 해서 최종적으로 사용한다.
아래 그림은 Fung Permadi v Indra라는 문장이 등장한 상황에서, 먼저 등장했던 Indra Wijaya beat Ong Ewe, And Indra said that... 문장들에서 Indra의 embedding을 가져와서 사용하는 과정을 보여준다.
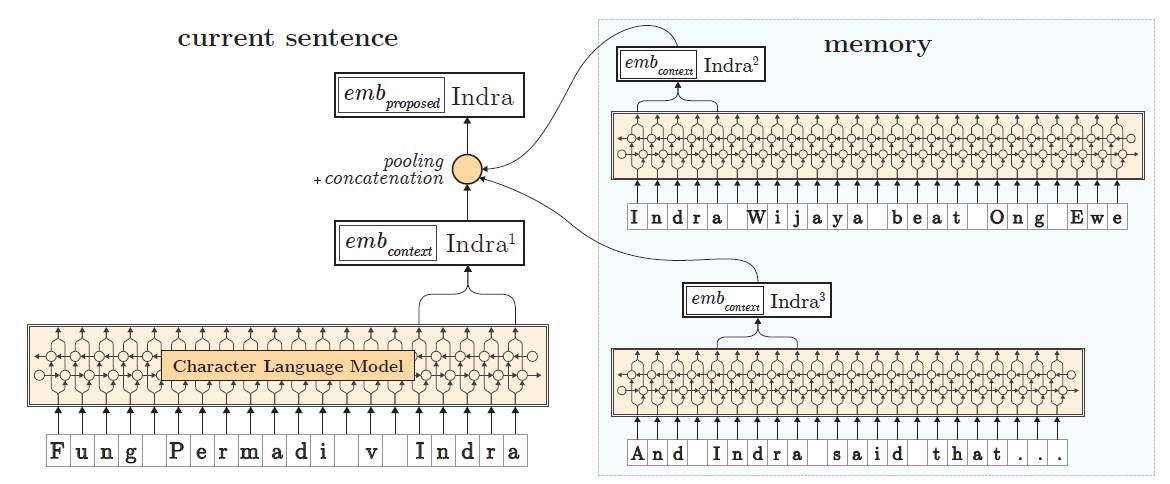
이전 연구와 마찬가지로, pretrain된 Character language model을 사용한다.
학습 데이터의 모든 문장들에 대해서 각 단어들의 embedding을 메모리에 저장한다.
해당 단어의 다른 embedding들이 메모리에 미리 저장되어 있다면 그 embedding들에 pooling을 적용한 후에, 현재 문장에서 얻은 embedding과 concat해서 해당 단어의 embedding으로 사용한다.
즉, 학습을 하면서 메모리가 계속 update되는 구조이다.
Pooling operations
같은 단어가 여러 문장에서 발생하는 경우, 메모리에 같은 단어에 대한 embedding이 여러개 존재하게 된다.
이런 경우에는 pooling을 적용하여 하나의 embedding으로 만든다.
Pooling은 mean, min, max pooling을 적용할 수 있다.
아래 그림은 NER task에서 이전 연구의 결과와 본 연구의 각 pooling들에 대한 결과를 보여준다.

Traning downstream models
학습을 진행하면서 메모리가 계속 update되지만 각 epoch이 시작될 때 마다 메모리를 초기화시킨다.
즉, epoch마다 학습 문장의 순서들이 달라지기 때문에 단어들의 embedding 역시 조금씩 달라지게 된다.
Evolving embeddings
본 연구의 방법을 사용하면 같은 문맥의 같은 단어라도 학습이 진행되면서 계속 embedding에 변화가 생긴다.
학습을 마친 후에는, 메모리를 초기화시키지 않고 계속 update하면서 단어들의 embedding을 발전시켜나간다.
즉, 학습이 끝난 후에도 계속해서 데이터로부터 embedding을 발전시킬 수 있다.
본 연구에서는 NER task에 대한 실험 결과만 보여주었지만, 메모리를 사용해 embedding을 update시킨다는 방법은 다른 task들에서도 유용하게 쓸 수 있을 것 같다.
논문 링크
NAACL 2019
Pooled Contextualized Embeddings for Named Entity Recognition
Leave a comment