
Contextual String Embeddings for Sequence Labeling
Sequence labeling은 NER(Named Entity Recognition), POS(Part Of Speech) tagging 처럼 여러 token들로 이루어진 sequnece를 분류하는 task를 말한다.
기존에는 sequence labeling에 LSTM과 CRF를 결합한 모델들을 많이 사용했다.
NLP task들에 큰 기여를 한 word embedding 방법은 크게 3가지가 있다.
- 가장 일반적인, pretain된 word 단위의 embedding,
ex) Word2Vec - Character 또는 subword 단위의 pretrain되지 않는 embedding,
ex) Transformer, BERT - 문맥 정보를 사용하는 word 단위의 embedding,
ex) ELMo
본 논문에서는 문맥 정보를 사용하는 character 단위의 embedding을 제안한다.
제안하는 embedding 방법과 BiLSTM-CRF를 사용해 당시 NER task에서 SOTA를 달성했다.
Contextual String Embeddings
문장을 character들의 sequence로 취급하여 character level language model에 input으로 주고 word level의 embedding을 만든다.
Recurrent Network States
Language model로써 BiLSTM을 사용한다.
즉, character를 input으로 주었을 때, 다음 character를 예측하도록 BiLSTM을 학습시킨다.
BiLSTM으로 representation을 얻고, linear layer와 softmax layer를 거쳐 다음 character의 확률을 계산한다.
Extracting Word Representations
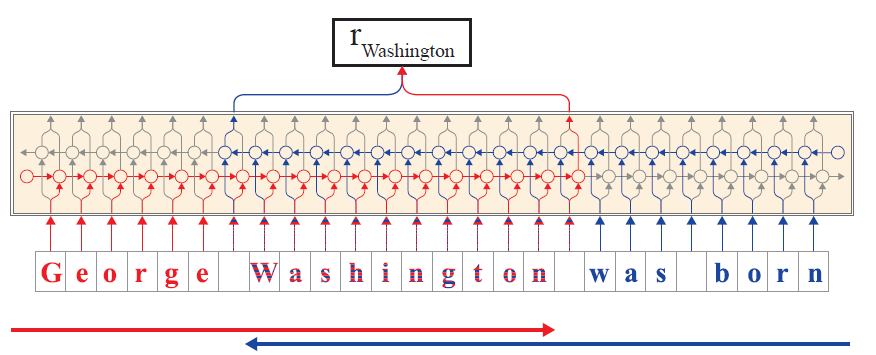
Character level BiLSTM의 forward와 backward 방향의 output으로 word level의 representation을 계산한다.
Forward 방향으로는 마지막 character의 다음 step의 hidden state를, backward 방향으로는 첫번째 character의 이전 step의 hidden state를 concat해서 word level의 representation을 얻는다.
\[\Large w_i^{\text{CharLM}}:= \begin{bmatrix}h^f_{t_{i+1}-1}\\h^b_{t_i}-1 \end{bmatrix}\\ w_i: \text{i번째 word}\\ t_i: w_i \text{ 가 시작되는 time step}\\ h^f: \text{forward 방향의 hidden state}\\ h^b: \text{backward 방향의 hidden state}\]아래 그림은 character의 sequence에서 Washington이라는 word의 embedding을 계산하는 과정이다.
빨간색은 forward, 파란색은 backward를 의미한다.
Sequence Labeling Architecture
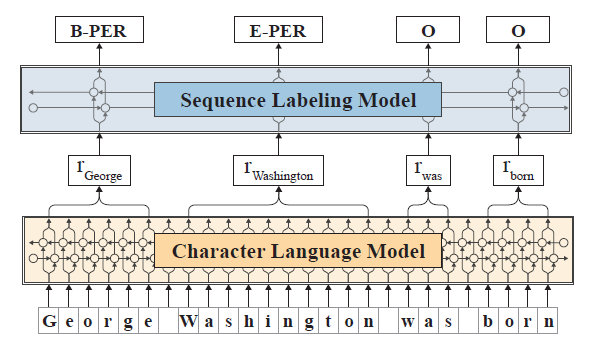
Character level BiLSTM으로 계산한 embedding을 BiLSTM-CRF 모델에 input으로 줘서 각 word들의 representation을 계산하고 class의 확률을 구한다.
Character level BiLSTM으로 계산한 word embedding들을 \(w_0, w_1,...,w_n\)이라고 할 때, 또 다른 BiLSTM의 output \(r_i\)를 구할 수 있다.
\[\large r_i = \begin{bmatrix}r_i^f\\r_i^b \end{bmatrix}\]\(r_i^f,r_i^b\)는 각각 \(w_i\)에 대한 BiLSTM의 forward, backward 방향의 output이다.
CRF로 \(r_i\)를 사용해 class \(y\)의 확률을 계산한다.
\[\large \hat{p}(y_{0:n}\mid r_{0:n})\propto\Pi_{i=1}^n \psi_i(y_{i-1},y_i,r_i)\\ \large \psi_i(y',y,r)=exp(W_{y',y}r+b_{y',y})\]여기서, \(W,b\)는 학습되는 파라미터이다.
또한, character level BiLSTM으로 계산한 word embedding과 기존의 다른 word embedding 방법을 같이 사용할 수도 있다.
GloVe와 같이 사용하면 \(w_i\)를 다음과 같이 만들 수 있다.
\[w_i=\begin{bmatrix}w_i^{CharLM}\\w_i^{GloVe} \end{bmatrix}\]아래 그림은 NER task에 적용하는 과정을 보여준다.
Leave a comment