
Character-Level Language Modeling with Deeper Self-Attention
Character level의 langauge model은 다음과 같은 어려움이 있다.
- 모델이 처음부터 많은 vocabulary를 학습해야 한다.
- 수백 또는 수천 time step들에 걸쳐 dependency를 갖는다.
- Character sequence는 word sequence보다 길기 때문에 많은 계산이 필요하다.
본 연구에서는 transformer 구조를 사용해서 non recurrent한 방법이 character level의 language model에서 좋은 성능을 낼 수 있다는 것을 보여준다.
Transformer 구조가 긴 sequence의 language model에 매우 적합하고, RNN 구조를 대체할 수 있다는 것을 확인했다.
본 연구에서는 기존의 transformer 구조에 몇가지 loss들을 추가했다.
Character Transformer Model
Language model은 길이가 \(L\)인 token들의 sequence에서 다음과 같이 확률을 계산한다.
\[P(t_{0:L})=P(t_0)\Pi_{i=1}^{L}P(t_i\mid t_{0:i-1})\]조건부 확률 \(P(t_i\mid t_{0:i-1})\)을 계산하기 위해 transformer network가 sequence \(t_{0:i-1}\)을 처리하도록 학습시킨다.
본 연구에서는 64개의 transformer layer를 사용했다.
여기서 transformer layer는 기존 transformer에서 사용되었던 multihead self attention sublayer와 feed forward FC sublayer로 이루어진 layer를 의미한다.
모델이 이전 character들에만 의존해 다음 character를 예측한다는 것을 보장하기 위해 attention layer에 mask를 사용했다.
즉, 각 position에서 왼쪽의 정보에만 attention을 적용한다.
아래 그림은 기본적인 mask를 적용한 transformer 모델의 구조를 보여준다.
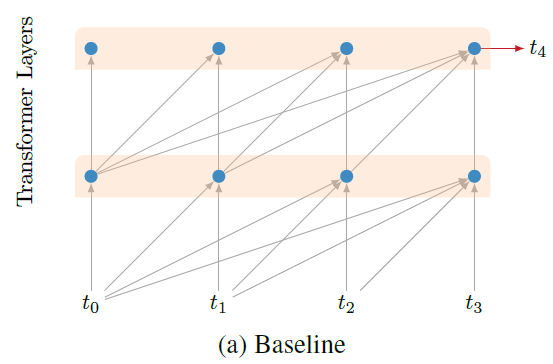
Auxiliary Losses
본 연구에서 사용한 모델은 기존의 transformer 모델들에 비해 깊은 모델이다.
모델의 layer 수가 많아지면 모델의 수렴이 느려지고 성능이 떨어지게 된다.
본 연구에서는 기존 transformer에 보조적인 loss들을 추가해서 수렴 속도를 향상시켰고, 그로 인해 모델을 더 깊게 만들 수 있었다.
다음 3가지에 대응되는 loss들을 추가했다.
-
Sequence의 중간 position들에서 다음 character를 예측
-
중간의 layer에서 다음 character를 예측
-
각 position들에서 다음 step 뿐 아니라, 여러 step의 character를 예측
이러한 보조 loss들은 모델의 수렴 속도를 향상시킬 뿐 아니라, 추가적인 일반화의 기능을 한다.
보조 loss들은 학습 과정에서 weight가 적용되어 감소된 상태로 모델의 loss에 더해지고 각각의 decay schedule을 갖는다.
Evaluation과 inference에서는 마지막 layer의 마지막 position에서의 예측만 사용한다.
즉 학습 과정의 파라미터 수와 inference 과정의 파라미터 수가 다르다고 할 수 있다.
Multiple Positions
먼저, 마지막 layer에서 각각의 position에서 다음 character의 예측을 수행함으로써, 하나의 data당 예측 수를 1번에서 sequence의 길이인 \(\mid L\mid\)번으로 증가시켰다.
Sequence의 모든 position에서 다음 character를 예측하는 것은 RNN 구조에서 일반적인 접근 방법이다.
하지만 본 연구에서는 batch들 사이에서 forward하게 전달되는 정보가 없다.
즉, 모델이 더 작은 context들을 예측하도록 만든다.
이러한 secondary task들이 전체 context를 예측하는 primary task에 도움을 준다는 것이 명백하지는 않지만, 학습 속도와 성능을 향상시켰다.
아래 그림은 이러한 secondary task를 추가한 구조를 보여준다.
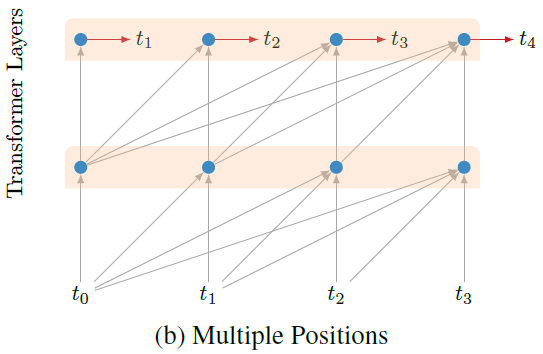
이 보조 loss에는 학습 과정에서 decay를 적용하지 않았다.
Intermediate Layer Losses
마지막 layer 뿐 아니라, 중간의 layer의 output에서도 예측을 수행한다.
마지막 layer와 마찬가지로 중간의 layer에도 모든 position에서 예측을 수행한다.
아래 그림은 이러한 구조를 보여준다.
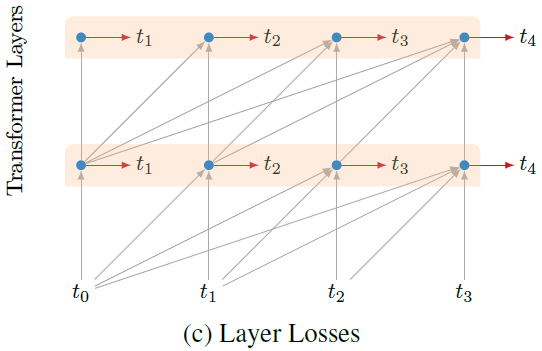
아래쪽의 layer들은 학습 과정에서 loss에 적은 기여를 하게 weight를 할당한다.
전체 \(n\)개의 layer가 있다고 하면, \(l\)번째 중간 layer는 전체 학습의 \(\frac{l}{2n}\)이 끝난 후에, loss를 만들지 않는다.
이러한 schedule 방법은 학습 과정의 절반이 끝나면, 모든 중간 layer들의 loss를 멈추게한다.
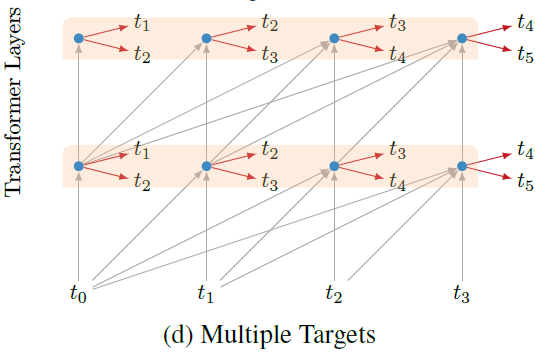
Multiple Targets
Sequence의 각 position에서 둘 이상의 다음 character들을 예측한다.
각 새로운 target마다 별개의 classifier를 사용한다.
새로운 target에서 만들어지는 loss는 0.5를 곱한 후에 해당 layer의 loss에 더해진다.
아래 그림은 이러한 구조를 보여준다.
Positional Embedding
기존 transformer 구조에서는 input에 sinusoidal 함수를 더했지만, 본 연구의 모델은 64 layer로 매우 깊은 모델이기 때문에 시간 정보가 layer들을 통과하면서 손실될 수 있다.
이를 해결하기 위해, layer 별로 학습된 positional embedding을 더한다.
이 모델은 \(L\)개의 position과 \(N\)개의 layer마다 각각 512 차원의 embedding vector를 학습한다.
즉, 총 \(L\times N\times 512\)개의 파라미터를 추가로 학습시킨다.
논문 링크
AAAI 2019
Character-Level Language Modeling with Deeper Self-Attention
Leave a comment