
Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
사람과 open domain topic에 대해서 자연스럽게 대화할 수 있는 챗봇에 대한 연구는 계속 진행되고 있다.
챗봇 시스템에서 중요한 task중 하나는 response selection, 즉, 주어진 대화의 context로 부터 얻은 response들의 후보 중에서 가장 적절한 response를 선택하는 것이다.
사람이 만든 response는 이전 대화의 다양한 granularities의 segment들에 많은 dependency를 가진다.
Granularities는 words, phrase, sentences 등을 의미한다.
즉, segment끼리 매칭될 때 segment pair는 word와 word 뿐 아니라, word와 phrase, phrase와 phrase 등 다양한 종류의 pair가 될 수 있다.
아래 그림은 context와 response의 관계, 매칭되는 segment pair들을 보여준다.

Context와 response 사이의 segement pair에는 크게 두 종류가 있다.
<packages,package>,<debian package manager,debian package manager>같이 표면적으로 overlap 되는 경우<it,dpkg>같이 의미적으로 연관되고 latent dependency를 갖는 경우
본 연구에서는 transformer에 기반한 attention 모델을 사용했다.
Self attention
문장 자체에 attention을 적용해서 word level의 dependency를 계산한다.
Phrase들은 word embedding과 word level self attention을 통해 representation으로 계산되고, 마찬가지로 sentence의 representation은 phrase level self attention으로 계산된다.
Hierachical한 self attention을 통해 여러 granularities에서의 semantic representation을 계산할 수 있다.
Cross attention
Context와 response 사이의 attention을 통해 segment pair들의 latent dependency를 계산한다.
여러 turn의 context로 부터 정보를 얻어 response를 매칭한다.
Deep Attention Matching Network(DAM)
Problem Formalization
대화 dataset \(D=[](c,r,y)_Z]_{Z=1}^N\)에 대해 \(c=[u_0,...,u_{n-1}]\)은 대화의 context, \([u_i]_{i=0}^{n-1}\)은 utterance, \(r\)은 response의 후보, 그리고 \(y\in \{0,1\}\)은 \(r\)이 \(c\)에 대한 적절한 response인지를 의미하는 label이다.
본 연구의 목적은 주어진 \(D\)에 대해 \(c\)와 \(r\)을 매칭시키는 model \(g(c,r)\)을 학습시키는 것이다.
Model Overview
아래 그림은 DAM의 구조를 보여준다.
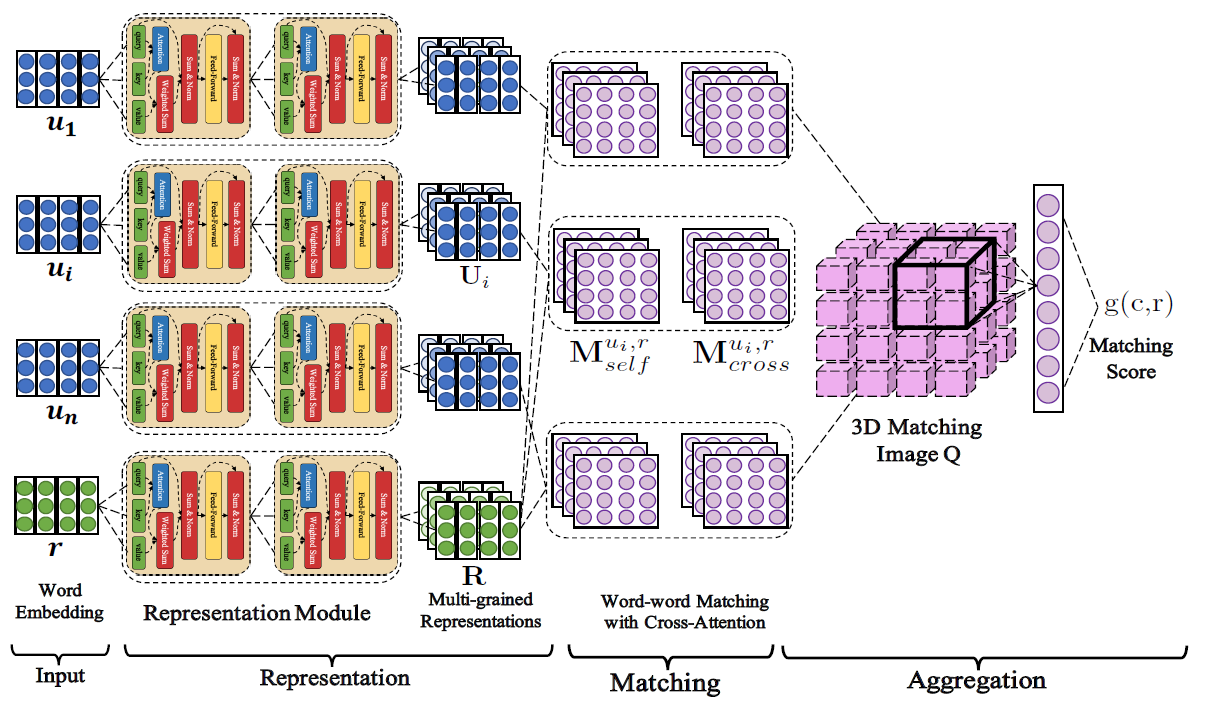
DAM은 response를 multi turn context와 매칭하기 위해 representation-matching-aggregation 구조를 따른다.
먼저, context 안의 각 utterance \(u_i=[w_{u_i,k}]_{k=0}^{n_{u_i}-1}\)와 response의 후보 \(r=[w_{r,t}]_{t=0}^{n_r-1}\)에 대해 공유되는 word embedding table을 보고 \(u_i\)와 \(r\)을 word embedding의 sequence로 만들고, 이를 각각 \(U_i^0=[e_{u_i,0}^0,...,e_{u_i,n_{u_i}-1}^0]\), \(R^0=[e_{r,0}^0,...,e_{r,n_r-1}^0]\)로 표기한다.
그 후, representation module이 \(u_i\)와 \(r\)의 representation을 계산한다.
Representation module은 \(L\)개의 동일한 self attention layer가 stack된 구조이다.
Representation module을 통해 \(u_i\)와 \(r\)의 multi grained representation \([U_i^l]_{l=0}^L\)과 \([R^l]_{l=0}^L\)이 계산된다.
즉 \(L\)개의 self attention layer를 통해 \(L\)개의 representation을 얻는다.
\([U_i^0,...,U_i^L]\)과 \([R^0,...,R^L]\)이 주어졌을 때, \(u_i\)와 \(r\)은 segment-segment similarity matrix로 매칭된다.
각 layer \(l\in[0,...,L]\)에 대해 self-attention-match \(M_{self}^{u_i,r,l}\)와 cross-attention-match \(M_{cross}^{u_i,r,l}\)이 만들어진다.
\(M_{self}^{u_i,r,l}\)는 utterance와 response 사이의 textual information을, \(M_{cross}^{u_i,r,l}\)는 utterance와 response 사이의 dependency information을 갖는다.
이 matching score들은 3D matching image \(Q\)로 합쳐진다.
\(Q\)의 각 dimension은 each utterance in context, each word in utterance ,each word in response를 표현한다.
그 후에, max pooling을 사용하는 convolution을 통해 segment pair들 사이의 중요한 matching information을 추출하고, single layer perceptron을 통해 하나의 matching score를 계산한다.
이 matching score는 response와 전체 context 사이의 matching 정도를 의미한다.
Self attention과 cross attention을 구현하기 위해 Attentive Module을 사용한다.
Attentive Module
아래 그림은 Attentive Module의 구조를 보여준다.
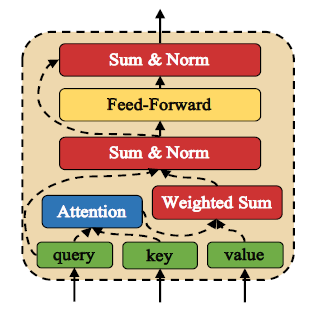
Attentive Module은 input으로 query \(Q=[e_i]_{i=0}^{n_Q-1}\), key \(K=[e_i]_{i=0}^{n_K-1}\) 그리고 value \(V=[e_i]_{i=0}^{n_V-1}\) 총 3개의 sentence를 입력 받는다.
여기서, \(n_Q,n_K,n_V\)는 각각 query, key, value의 word의 수를 의미하고, \(e_i\)는 \(d\) 차원의 embedding을 의미하며 \(n_K\)와 \(n_V\)는 같다.
Attentive Module은 먼저, query의 각 word들과 key의 word들에 Scaled Dot Product Attention을 사용해 score를 계산하고, 이 score를 value에 적용한다.
\[Attention(Q,K)=[softmax(Q[i]\cdot K^T)]_{i=0}^{n_Q-1}\\ V_{att}=Attention(Q,K)\cdot V\\ V_{att}\in\mathbb{R}^{n_Q\times d}\]여기서 \(Q[i]\)는 query의 \(i\)번째 embedding 값이다.
\(V_{att}\)의 각 row, \(V_{att}[i]\)는 query의 \(i\)번째 word에 대한 dependency를 갖는 value의 word이다.
그 후에, \(V_{att}[i]\)와 \(Q[i]\)가 더해진 후에 layer normalization을 적용하고 ReLU를 activation으로 사용하는 feed forward network \(FFN\)에 입력된다.
\[FFN(x)=max(0,xW_1+b_1)W_2+b_2\]\(x\)는 \(Q\)와 같은 형태의 tensor이며 \(W_1,b_1,W_2,b_2\)는 학습되는 parameter이다.
그 후에, \(x\)와 \(FFN(x)\)가 residual하게 더해지고 다시 layer normalization이 적용되어 Attentive Module의 output이 출력된다.
\[x=LayerNorm((Attention(Q,K)\cdot V)+Q)\\ AttentiveModule(Q,K,V)=LayerNorm(FFN(x)+x)\]이런 과정을 거쳐, query와 key의 dependency를 계산할 수 있다.
또한, 이러한 Attentive Module의 특성을 사용해 multi grained representation을 구한다.
Representation
Utterance의 word embedding \(U_i^0\) 또는 response의 word embedding \(R^0\)이 주어졌을 때, DAM은 \(U_i^0\) 또는 \(R^0\)를 input으로 받아 hierachical하게 Attentive Module을 쌓아올려 multi grained representation을 계산한다.
\[U_i^{l+1}=AttentiveModule(U_i^l,U_i^l,U_i^l)\\ R^{l+1}=AttentiveModule(R^l,R^l,R^l)\]여기서, \(l\)은 \(0\)부터 \(L1\) 까지이며, 서로 다른 granularity의 level들을 의미한다.
이렇게 얻은 multi grained representation을 \([U_i^0,...,U_i^L]\)과 \([R^0,...,R^L]\)로 표현한다.
Utterance-Response Matching
주어진 \([U_i^l]_{l=0}^L\)과 \([R^l]_{l=0}^L\)에 대해, 각 granularity의 level \(l\)에서 self-attention-match \(M_{self}^{u_i,r,l}\)과 cross-attention-match \(M_{cross}^{u_i,r,l}\)이 만들어진다.
\(M_{self}^{u_i,r,l}\)은 아래와 같이 정의된다.
\[M_{self}^{u_i,r,l}=\{U_i^l[k]^T\cdot R^l[t]\}_{n_{u_i}\times n_r}\]Matrix에서 각 element는 \(U_i^l\)의 \(k\)번째 embedding인 \(U_i^l[k]\)와 \(R^l\)의 \(t\)번째 embedding인 \(R^l[t]\)의 dot product의 결과이다.
이 element들은 \(l\)번째 granualrity에서의 \(u_i\)의 \(k\)번째 segment와 \(r\)의 \(t\)번째 segment의 dependency를 반영한다.
Cross-attention-match는 아래와 같이 정의된다.
\[\tilde{U}_i^l=AttentiveModule(U_i^l,R^l,R^l)\\ \tilde{R}^l=AttentiveModule(R^l,U_i^l,U_i^l)\\ M_{cross}^{u_i,r,l}=\{\tilde{U}_i^l[k]^T\cdot \tilde{R}^l[t]\}_{n_{u_i}\times n_r}\]Self attention과는 다르게 \(U_i^l\)과 \(R^l\)을 cross하게 attention을 적용시켜 \(\tilde{U}_i^l\)과 \(\tilde{R}^l\)를 만든다.
\(\tilde{U}_i^l\)과 \(\tilde{R}^l\)는 utterance와 response 사이의 semantic한 구조에 대한 정보를 갖는다.
이런 방법으로 inter-dependency를 갖는 두 segment pair의 dot product 연산을 통해 dependency information을 갖는 matching matrix를 계산한다.
Aggregation
DAM은 마지막으로 utterance와 response의 segment matching degree, 즉, matching matrix들의 각 element들을 하나의 3D matching image \(Q\)로 축약시키고 \(Q\)는 다음과 같이 정의한다.
\[Q=\{\mathbb{Q}_{i,k,t}\}_{n\times n_{u_i}\times n_r}\]각 픽셀 \(\mathbb{Q}_{i,k,t}\)는 아래와 같이 정의한다.
\[\mathbb{Q}_{i,k,t}=[M_{self}^{u_i,r,l}[k,t]]_{l=0}^L\oplus [M_{cross}^{u_i,r,l}[k,t]]_{l=0}^L\]여기서, \(\oplus\)는 concat 연산을 의미하고 각 픽셀은 \(2(L+1)\)개의 채널을 가지며, 하나의 segment pair 사이의 matching degree를 저장한다.
그 후에, DAM은 3D convolution과 max pooling을 적용해 전체 이미지 \(Q\)에서 중요한 matching feature들을 추출한다.
추출된 matching feature\(f_{match}(c,r)\)에 single layer perceptron을 적용해 최종적으로 matching score \(g(c,r)\)을 계산한다.
\[g(c,r)=\sigma(W_3f_{match}(c,r)+b_3)\]여기서, \(W_3,b_3\)은 학습되는 파라미터이며 \(\sigma\)는 sigmoid 함수이다.
DAM의 loss는 NLL로, 다음과 같이 정의한다.
\[p(y\mid c,r)=g(c,r)y+(1-g(c,r))(1-y)\\ L(\cdot)=-\sum_{(c,r,y)\in D}log(p(y\mid c,r))\]논문 링크
ACL 2018
Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
Leave a comment