
Deep contextualized word representations(ELMo)
Pretrained word representation 방법은 language understanding 분야에서 중요한 요소이다.
하지만, 높은 수준의 representation을 학습하는 것은 어려운 문제이다.
모델은 syntax나 semantic 같은 단어의 복잡한 특성들을 학습해야하고, 이러한 특성들이 문맥에 따라 어떻게 바뀌는지를 학습해야한다.
본 연구에서는 새로운 deep contextualized word representation을 소개한다.
기존의 방법들은 token들을 각각 하나의 representation으로 매핑하는 방법을 사용했다.
본 연구에서는 거대한 text corpus에서 language model로 학습된 bidirectional LSTM을 통해 얻은 vector를 사용한다.
여기서, ELMo(Embeddings from Language Models)라는 이름을 붙였다.
각각의 input 위에 stack 구조로 vector를 쌓아 결합시키고, LSTM의 마지막 layer만 사용한다.
Internal state들을 결합시키는 것은 매우 깊은 word representation을 만들 수 있게 한다.
Higher-level의 LSTM state는 단어들의 의미를 문맥에 의존해 파악할 수 있다.
반면에, lower-level의 state는 syntax의 관점에서 의미를 파악할 수 있다.
즉, state들을 결합시킴으로써 이러한 의미들을 모두 학습할 수 있다.
ELMo: Embeddings from Language Models
기존의 word representation들과는 달리, ELMo는 input 문장 전체를 표현한다.
이는 bidirectional language model의 가장 위의 layer에서 character convoultion을 사용해 계산된다.
이러한 방법은 pretrain된 language model을 NLP task에서 semi supervised 방식으로 학습할 수 있게 한다.
Bidirectional language models(BiLMs)
N개의 token의 sequence \((t_1,...t_N)\)이 주어졌을 때, forward language model은 다음과 같이 sequence의 확률을 계산한다. \(p(t_1,...,t_N)=\Pi_{k=1}^Np(t_k\mid t_1,...,t_{k-1})\) 이전의 language model들은 token embedding이나 character CNN 구조를 통해 문맥에 독립적인 token representation \(X_k^{LM}\)을 계산하고 이를 L개의 layer의 forward LSTM에 입력했다.
각 position \(k\)에서 각 LSTM layer는 문맥에 의존적인 representation \(\overrightarrow{h}_{k,j}^{LM}\)를 출력한다.
여기서 \(j\)는 layer를 의미하며, \(j=1,...,L\)이다.
가장 위의 layer의 출력 \(\overrightarrow{h}_{k,L}^{LM}\)은 softmax layer를 통해 다음 token \(t_{k+1}\)을 예측할 때 사용한다.
Backward language model은 sequence를 아래와 같이 반대 방향으로 처리한다는 것을 제외하고는 forward와 유사하다. \(p(t_1,...,t_N)=\Pi_{k=1}^Np(t_k\mid t_{k+1},t_{k+2},...,t_N)\) Backward 방향으로는 주어진 \((t_{k+1},...,t_N)\)으로 \(t_k\)의 representation \(\overleftarrow{h_{k,j}^{LM}}\)을 계산한다.
BiLM은 forward와 backward를 결합해서 아래와 같이 양방향의 loglikelihood를 최대화시킨다. \(\sum_{k=1}^Nlog\,p(t_k\mid t_1,...,t_{k-1};\Theta_x,\overrightarrow{\Theta}_{LSTM},\Theta_s)+log\,p(t_k\mid t_{k+1},...,t_N;\Theta_x,\overleftarrow{\Theta}_{LSTM},\Theta_s)\) Token representation의 파라미터 \(\Theta_x\)와 softmax layer의 파라미터 \(\Theta_s\)를 forward와 backward에서 묶어서 학습시킨다.
반면에, LSTM의 파라미터는 \(\overrightarrow{\Theta}_{LSTM}\)과 \(\overleftarrow{\Theta}_{LSTM}\)로 분리시켜 학습시킨다.
ELMo
ELMo는 biLM의 중간 layer representaion들을 task specific에 결합시킨 것이다.
각 token \(t_k\)에서 \(L\) layer의 bidirectional LSTM이 \(2L+1\)의 representation을 계산한다. \(R_k=\{x_k^{LM},\overrightarrow{h}_{k,j}^{LM},\overleftarrow{h}_{k,j}^{LM}\mid j=1,...L\}\\ =\{h_{k,j}^{LM}\mid j=0,...,L\}\:\:\:\:\:\:\:\:\:\:\:\;\:\:\:\) 여기서, \(h_{k,0}^{LM}\)은 token layer이고, 각 LSTM layer에서 \(h_{k,j}^{LM}=[\overrightarrow{h}_{k,j}^{LM};\overleftarrow{h}_{k,j}^{LM}]\) 이다.
Downtream task에 적용시키기 위해서, ELMo는 모든 layer를 하나의 vector \(R\)로 만든다. \(ELMo_k=E(R_k;\Theta_e)\) 가장 단순하게는 가장 위의 layer를 선택해서 \(E(R_k)=h_{k,L}^{LM}\)로 만들 수 있다.
일반적인 경우, 모든 layer의 task specific weight를 계산해서 아래와 같이 적용한다. \(ELMo_k^{task}=E(R_k;\Theta^{task})=\gamma^{task}\sum_{j=0}^Ls_j^{task}h_{k,j}^{LM}\) 여기서, \(s^{task}\)는 softmax를 거쳐 정규화된 weight이고, \(\gamma^{task}\)는 scalar 파라미터로, 전체 ELMo vector를 scaling한다.
각 biLM layer들의 activation들은 다른 분포를 갖기 때문에, 각 layer들에 weight를 곱하기 전에 layer normalization을 적용하는 효과를 얻을 수 있다.
Using biLMs for supervised NLP tasks
Pretrained biLM과 특정 NLP task를 위한 supervised 구조가 주어졌을 때, biLM을 적용하는 것은 간단하다.
각 단어에 대한 biLM의 모든 layer의 representation을 저장하고 task 모델에 이 representation들을 학습시킨다.
먼저, biLM 없이 supervised 모델을 고려해보면, 대부분의 supervised NLP 모델들은 가장 아래 layer를 공유한다.
이는 일관성 있고 통일되게 ELMo를 추가할 수 있게 해준다.
Token의 sequence \((t_1,...,t_N)\)이 주어졌을 때, pretrained word embedding을 사용해 문맥에 독립적인 token representation \(x_k\)를 만드는 것이 일반적이다.
그 후에, 모델은 bidirectional RNN, CNN, feed forward network 등을 사용해 문맥에 의존적인 representation \(h_k\)를 만든다.
Supervised 모델에 ELMo를 추가하기 위해서는 먼저 biLM의 weight들을 freeze할 필요가 있다.
그 후에, ELMo vector \(ELMo_k^{task}\)를 \(x_k\)와 concat해서 \([x_k;ELMo_k^{task}]\)를 task RNN에 전달한다.
아래 그림은 ELMo를 다른 embedding 방법과 결합해 NLP task에 적용하는 과정을 보여준다.
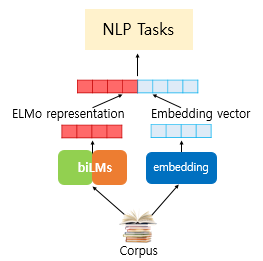
본 연구에서는 SNLI, SQuAd 같은 몇몇 task에서, task RNN의 출력에도 ELMo를 더해서 \(h_k\)를 \([h_k;EMLo_k^{task}]\)로 대체함으로써 성능을 향상시킬 수 있었다.
또한, ELMo에 dropout을 추가하거나 loss에 \(\lambda\mid \mid w\mid \mid^2_2\)를 더해서 ELMo weight들을 정규화시키는 것이 효과적이라는 것을 발견했다.
이는 모든 biLM layer의 평균에 가까워지도록 ELMo weigth들에 bias를 부여한다.
Pretrained bidirectional language model architecture
본 연구에서 pretrained biLM은 양방향을 joint하게 학습하며, LSTM layer들 간에 residual connection을 추가했다.
모델은 \(L=2\) biLSTM layer로, 각각의 layer들은 4096 크기의 unit과 512 크기의 projection을 가지며 첫번째와 두번째 layer는 residual connection을 갖는다.
문맥의 representation은 2048개의 character n-gram convolution filter를 사용하고, 그 후에 2개의 highway layer와 512 크기의 linear projection을 적용한다.
그 결과, 일반적인 word embedding 방법들은 각 token들이 하나의 layer만 통과하는 반면, biLM은 각각의 input token들이 3개의 layer를 통과하도록 한다.
아래 그림은 token이 처리되는 과정을 보여준다.
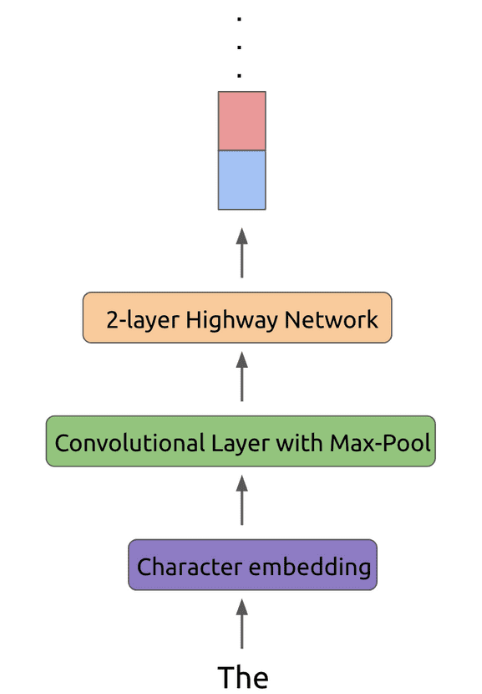
한번 학습되면 biLM은 어떤 task에도 적용할 수 있도록 representaion을 계산할 수 있다.
어떤 task들에서는 biLM을 finetuning 하는것이 성능을 향상시킬 수 있다.
아래 그림은 ELMo가 happy라는 token의 representation을 계산하는 과정을 보여준다.
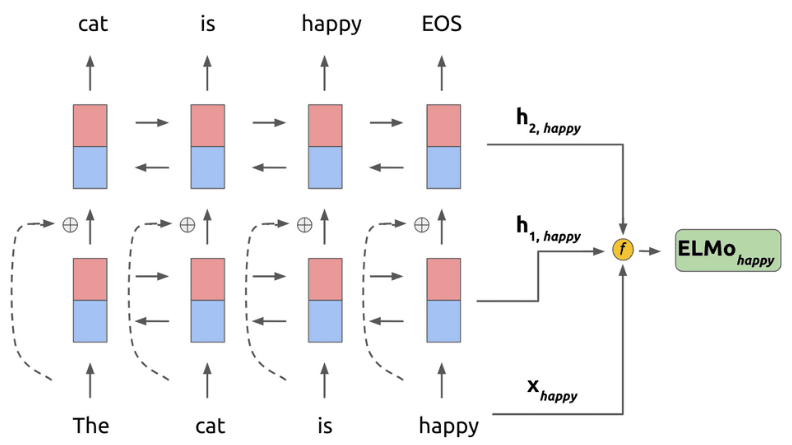
이런 과정을 통해 token들의 ELMo representation을 계산하고, 이 representation을 token의 embedding \(x_k\)과 결합해서 NLP task에 사용할 수 있다.
Leave a comment