
Zero-shot Learning of Classifiers from Natural Language Quantification
Siri, Alexa, Google Home 같은 사용자들과 상호작용하는 시스템들이 발전하고 있다.
이러한 시스템들은 사용자들이 언어로 machine을 가르칠 수 있다는 가능성을 보여주고 있다.
언어로부터 학습하는 이러한 능력은 학습 데이터가 없거나 제한되는 상황에서도 사용자들이 개인적인 concept들을 machine에게 가르칠 수 있게 한다.
본 연구에서는 quantifier를 사용해 classifier들을 학습시키고 이러한 task를 해결한다.
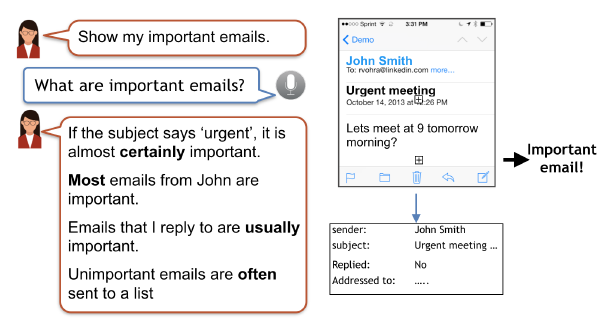
위의 그림에서, 사용자가 important email이라는 concept을 machine에게 가르치고 있다.
Emails that I reply to are usually important라는 언어를 통해 important email을 분류하는 binary classifier를 학습시킬 수 있다.
Concept을 설명하는 언어가 주요한 특성들을 encoding 한다는 가설을 세웠다.
이것은 다음 내용들을 포함한다.
- 연관된 특성들의 specification
ex) whether an email was replied to
- 특성과 concept label과의 관계
ex) if a reply implies the class label of that email is 'important'
- 이러한 관계의 정도
ex) 'often', 'sometimes', 'rarely'
본 연구에서는 이러한 특성들을 자동으로 추론하고 linguistic quantifier의 semantic을 사용해서 그 concept의 labeled 데이터 없이 classifier를 학습시킨다.
기존의 semi supervised, constraint based learning은 이러한 문제에 적용시키기 위해서는 전문가의 지식이 필요했고, 모델을 학습시킬 때 수동으로 미리 specification을 만들어야 했다.
본 연구에서는 이러한 것들이 사용자의 설명으로부터 자동으로 학습된다.
아래 그림은 전체적인 구조이다.
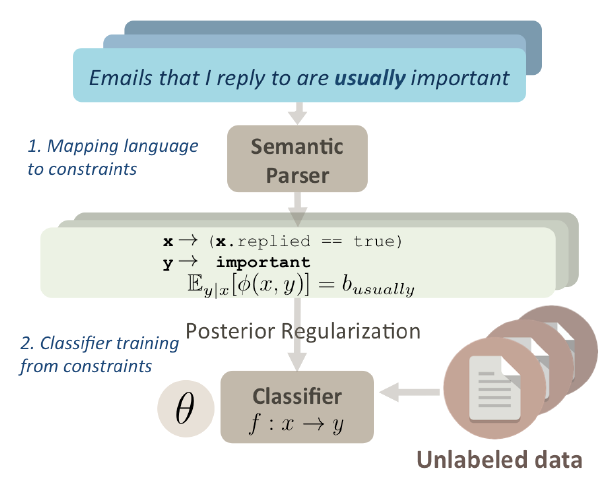
먼저, concept에 대한 설명을 logical form으로 만든다.
이 logical form은 설명에서 언급된 특성들을 인식하고, 전달된 특성과 concept label에 대해 정량적인 정보를 설명한다.
매핑은 semantice parsing을 통해 이루어진다.
Logical form에서 정량은 'all', 'some', 'few' 등의 linguistic quantifier를 사용해 나타낸다.
다음으로, posterior regularization으로 classifier를 학습시킨다.
직관적으로, 최적화 문제로 볼 수 있는데, 여기서 목표는 단순히 데이터에 의해 학습되는 것이 아니라 사용자가 가르치는 언어에 의해 학습되는 classifier를 찾는 것이라고 볼 수 있다.
Logical form은 다양한 resource들에 기반할 수 있기 때문에, 모델이 유연한 범위의 정보들을 이해하고 행동할 수 있게 된다.
본 연구의 주요 contribution은 아래와 같다.
- Language classifier의 zero shot learning을 소개하고 방법을 제안했다.
- Language classifier의 zero shot learning을 위한 dataset을 개발했다.
- Linguistic qunatifier를 모델링하기 위한 대략적인 확률 추정치가 모델을 훈련함에 있어 효과적인 supervisor가 될 수 있음을 보였다.
Learning Classifiers from Language
가장 먼저 할 일은 언어적인 설명을, 설명된 특성과 concept label의 관계를 확률적으로 표현할 수 있는 정량적인 형태로 바꾸는 것이다.
그 후에, 정량화된 정보를 classifier의 학습에 사용한다.
문장들을 정량적으로 이해하기 위해 semantic parsing을 사용하고 posterior regularization을 적용해 classifier의 파라미터들을 추정한다.
본 연구에서 학습은 linguistic qunatifier의 semantic에 의해 이루어지기 때문에, LNQ(Learning from Natural Quantification)이라고 이름을 붙였다.
Mapping language to constraints
언어로부터 학습함에 있어 해결해야 할 것은 형식이 없는 언어를 데이터에 기반하는 representation으로 변환하는 것이다.
예를 들면, Emails that I reply to are usually important라는 문장을 \(P(important\mid replied:true)=0.7\)로 변환할 필요가 있다.
이러한 과정들은 많은 실제의 설명 데이터들에 의해 자동으로 이루어진다.
Concept을 설명하는 문장들을 이해함에 있어, 아래와 같은 주요 element들을 추론한다.
-
관측된 특성들에 기반한 feature \(x\)
예를 들면,
Emails replied to는 \(replied:true\)로 정의될 수 있다.Representation들을 통합하는 것은 보다 복잡한 추론을 가능하게 해준다.
예를 들면,
The subject of course-related emails usually mentions CS100은 \(isStringMatch(field:subject,stringVal('CS100'))\)으로 매핑될 수 있다.여기서는 하나의 문장이 하나의 feature를 언급한다고 가정하지만, 더 복잡한 설명들을 다루도록 확장될 수 있다.
-
Concept label \(y\)
문장에서 언급한 class를 구체화한다.
Binary class에서는 concept의 예시인지 아닌지로 나눈다.
본 연구에서는 \(y\)는 important email에 대한 positive class이다.
-
문장에서 기술된 constraint의 type
대부분의 concept은 \(P(y\mid x)\), \(P(x\mid y)\), \(P(y)\) 3개의 카테고리에 속한다.
이것들은 본 연구의 constraint type의 vocabulary를 구성한다.
Emails that I reply to are usually important는 \(P(y\mid x)\)에 속하고,I usually reply to important emails는 \(P(x\mid y)\)에 속한다. -
Stength of constraint
Strength는 quantifier에 의해 설명된다고 가정한다.
Emails that I reply to are usually important에서'usually'가 이에 해당한다.본 연구에서는
'usually, 'rarely', 'few', 'all'등이 quantifier로 정해진다.Quantifier의 semantic은 설명된 특성과 concept label 사이의 관계를 확률적으로 표현할 수 있다.
아래 테이블은 몇몇 quantifier들에 probability를 직관적으로 할당한 것이다.
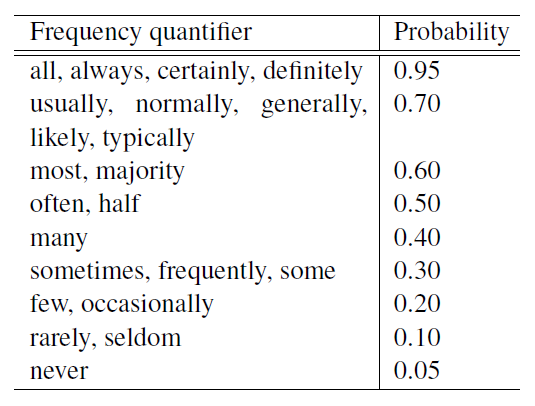
출처:https://www.aclweb.org/anthology/P18-1029
문장들을 형식적인 semantic representation으로 매핑하기 위해 semantic parsing 모델을 사용한다.
예를 들면, Emial that I reply to are usually important는 아래와 같은 형태의 logical form으로 매핑할 수 있다.
\(x\rightarrow replied:true\\
y\rightarrow positive\\
type:y\mid x\\
quant:usually\)
Semantic Parser components
설명 문장 \(s\)가 주어졌을 때, parsing은 그 문장을 가장 잘 표현하는 logical form \(l\)을 예측하는 문제이다.
Logical form \(l\)을 아래와 같이 공식으로 표현한다. \(P(l\mid s)=P(l_{xy}\mid s)P(l_{type}\mid l_{xy},s)P(l_{quant}\mid s)\) 여기서, \(l_{xy}\)는 concept label, \(l_{type}\)은 constraint의 type 그리고 \(l_{quant}\)는 linguistic quantifier를 의미한다.
\(P(l_{xy}\mid s)\)에서는 일반적인 semantic parser를 사용했다.
\(P(l_{type}\mid l_{xy},s)\)에서는 Max-Ent classifier를 학습시켰다.
\(P(l_{quant}\mid s)\)에서는 quantifier와 매칭되는 문자열을 찾았다.
Identifying features and concept labels, \(l_{xy}\)
Feature와 concept label을 정의하기 위해 linear score \(S(s,l_{xy})=w^T\psi(s,l_{xy})\)를 가정한다.
여기서 \(\psi(s,l_{xy})\)는 부분적인 logical form \(l_{xy}\)가 \(s\)에 잘 할당 되었는지 정도를 나타낸다.
\(\psi(s,l_{xy})\in \mathbb{R}^n\)은 문장과 logical form 모두에 의존하는 feature이다.
\(w\in \mathbb{R}^n\)은 weight vector이다.
문장을 이해하기 위해 다음과 같은 log-linear 분포를 가정한다. \(P(l_{xy}\mid s)\propto w^T\psi(s,l_{xy})\) Label이 있는 문장과 logical form이 주어지면, 모델은 MLE 방식으로 학습되고 새로운 문장을 예측한다.
이 학습을 위해서 CCG(Combinatory Categorial Grammar) semantic parsing formalism을 사용했다.
Identifying assertion type, \(l_{type}\)
본 연구의 semantic parsing에 있어 참신한 점은 constraint의 type을 식별하는 과정에서 발견할 수 있다.
Constraint의 type을 예측하기 위해 문장에서 언급된 feature와 concept에 대응하는 text span에 기반한 positional하고 syntactic한 feature를 사용하는 Max-Ent classifier를 학습시킨다.
문장으로부터 다음의 feature들을 추출한다.
- Feature \(x\)에 대응하는 text span이 concept label \(y\)에 대응하는 text span보다 앞에 나오는지를 나타내는 boolean value
- 문장이
nsubjpassdependency relation에 의해, actvie 보다는 passive voice에 속하는지를 나타내는 boolean value - \(x\)에 대응하는 text span의 head가 명사인지, 동사인지를 나타내는 boolean value
'if', 'then', 'that'같은 conditional token들이 \(x,y\)의 text span의 앞 또는 뒤에 있는지를 나타내는 feature- \(x\) 또는 \(y\)의 syntactic head와
det또는advmodrelation을 갖는 linguistic quantifier의 존재를 나타내는 feature
Constraint type은 syntactic과 dependency parse feature들에 의해 결정되기 때문에 이 학습은 새로운 domain에서 재학습될 필요가 없다.
본 연구에서는 이 classifier를 UCI Zoo dataset으로 학습시키고 모든 실험에서 이 모델을 사용했다.
Identifying quantifiers, \(l_{quant}\)
하나의 문장에 다수의 liguistic quantifier가 나오는 경우는 드물다.
본 연구에서는 문장에서 처음으로 등장하는 quantifier를 찾았다.
Emails from my boss are important 처럼 확실한 quantifier가 존재하지 않는 문장은 학습에서 제외했다.
Logical representation으로 부터 quantification을 분리하는 것도 중요하다.
언어의 특성으로 인해, logical representation에 관계 없이 quantification을 모델링하는 것이 가능하다.
Classifier tranining from constraints
Classifier를 학습시키기 위해 사용자가 제공한 설명들이 어떻게 unlabeled 데이터와 함께 사용되는지를 설명한다.
본 연구의 접근은 classifier가 사용자가 제공한 설명들에 기반해 unlabeld 데이터, \(X=\{x_1,...,x_n\}\)을 예측하는 것에 있다.
관측되지 않은 concept label, \(Y=\{y_1,...,y_n\}\)는 latent variable을 구성한다.
학습 과정은 제공된 설명에 기반해 unlabeled 데이터의 latent concept label을 추론하고, 주어진 label로 classifier를 업데이트하는 과정을 반복하는 것으로 볼 수 있다.
Constraint로 부터 statistical model을 학습시키기 위해 PR(Posterior Regularization) framework을 사용했다.
Porsterior Regularization의 목적 함수는 posterior distribution, \(p_{\theta}(Y\mid X)\)의 선호도 value를 구체화하는 constraint들에 따른 latent variable model을 최적화하는데 사용할 수 있다. \(J_Q(\theta)=\mathcal{L}(\theta)-min_{q\in Q}KL(q\mid p_{\theta}(Y\mid X))\) 여기서, \(Q\)는 latent variable \(Y\)에 대해, 선호되는 posterior distribution의 집합이고 아래와 같이 정의한다. \(Q:=\{q_X(Y):\mathbb{E}_q[\phi(X,Y)]\leq b\}\) 전체적인 목적 함수는 어떻게 모델 \(\theta\)가 데이터를 잘 설명할지, 즉, likelihood \(\mathcal{L}(\theta)\)와 얼마나 \(Q\)에 가까워질지, 즉, KL-divergence 두 부분으로 이루어진다.
본 연구에서 parsing된 각 문장들은 확률적인 constraint를 정의한다.
모든 constraint들의 결합은 \(Q\)를 정의하고, 이는 정확하게 사용자들이 제공한 설명에 일치하는 모델을 표현한다.
그러므로, 목적 함수를 최적화시키는 것은 데이터의 likelihood를 증가시키고, 사용자들의 언어적인 설명을 흉내낼 수 있도록 하는 것이다.
Converting to PR constraints
PR이 다룰 수 있는 constraint들의 집합은 \(X,Y\)의 예상 값의 경계로 취급될 수 있다.
이 framework를 사용하기 위해 vocabulary안의 각 constraint type들이 하나의 형태로 표현될 수 있어야 한다.
각 constraint type은 \(\mathbb{E}_q[\phi(X,Y)]=b\)의 형태로 바뀔 수 있다.
특히, vocabulary안의 constraint type들은 할당된 label과 특성들간 joint indicator function의 기댓값으로 표현될 수 있다.
예를 들면, \(P(y=important\mid replied:true)=p_{usually}\)라고 할때, 아래와 같이 표현될 수 있다. \(p_{usually}=\frac{\sum_i\mathbb{E}[\mathbb{I}_{y_i=important,replied:true}]}{\sum_i\mathbb{E}[\mathbb{I_{replied:true}}]}\) 여기서, \(\mathbb{I}\)는 indicator function을 의미한다.
그러므로, 본 연구에서는 확률적인 constraint들을 PR에 적용시켰다고 할 수 있다.
아래 테이블은 일반적인 constraint type과 그 representation을 나타낸다.

Learning and Inference
Concept classifier를 위해 loglinear parameterization을 선택했다. \(p_{\theta}(y_i\mid x_i)\propto exp(y^{\theta^T}x)\) Classifier의 학습은 EM 방식을 사용했다.
PR 목적 함수는 \(L_2\) regularize를 적용했고, 아래와 같은 식을 얻을 수 있다. \(J'(\theta,q)=\mathcal{L}(\theta)-KL(q\mid p_{\theta}(Y\mid X))-\lambda\parallel\mathbb{E}_q[\phi(X,Y)]-b\parallel^2\) 학습에 있어 주요 단계는 아래처럼 E-step에서 posterior regularizer를 계산하는 것이다. \(argmin_q\,KL(q\mid p_\theta)+\lambda\parallel\mathbb{E}_q[\phi(X,Y)]-b\parallel^2\) 이 목적 함수는 convex이고, \(q\)에서 모든 constraint들은 linear이다.
E-step에서는 gradient 방식으로 최소화 문제를 효율적으로 해결할 수 있고, M-step에서는 E-step에서 추정한 label distribution \(q\)를 기반으로 classifier의 파라미터를 업데이트한다.
이것은 logistic regression의 파라미터 \(\theta\)를 추정하는 것으로 단순화할 수 있다.
본 연구에서는 모든 실험에서 EM 과정을 20 iteration 동안 진행했고, \(\lambda=0.1\)로 설정했다.
논문 링크
ACL 2018
Zero-shot Learning of Classifiers from Natural Language Quantification
Leave a comment