
기계 번역
1. 개발 도구
- Python3
- Pytorch
- Sentencepiece
- nltk
2. 데이터
IWSLT 2016 영어-독일어 데이터 사용 (데이터 제공)
20만개의 영어-독일어 학습 데이터 쌍을 사용해 모델을 학습하고 1천개의 테스트 데이터 쌍으로로 모델의 성능을 검증


3. 전처리
토크나이저 학습
BPE 기반의 토크나이저인 Google의 SentencePiece를 사용
영어-독일어 문장 데이터를 입력으로 주고, 사전의 크기는 <PAD>, <UNK>, <BOS>, <EOS> 토큰들을 포함해 32000이 되도록 토크나이저를 학습
문장 토큰화
학습한 토크나이저로 데이터 문장들을 토큰화


데이터 처리
Pytorch에서 제공하는 Dataset을 사용해 영어-독일어 쌍을 하나의 데이터로 처리하는 CustomDataset을 만듬
Custom collate 함수를 만들고 Pytorch에서 제공하는 DataLoader를 사용해 batch 단위로 영어-독일어 쌍 데이터를 읽음
4. 모델
Transformer
Pytorch로 Attention is all you need 논문에 소개된 기본적인 transformer 모델을 구현
<PAD> 토큰에 masking을 적용해 attention score를 계산할 때, query가 key의 <PAD> 토큰에 관여하는 것을 방지
모델 학습
모델의 layer 수는 6, attention head 수는 8, \(d_{model}\)은 512, \(d_{ff}\)는 2048, 데이터의 최대 길이는 150으로 지정
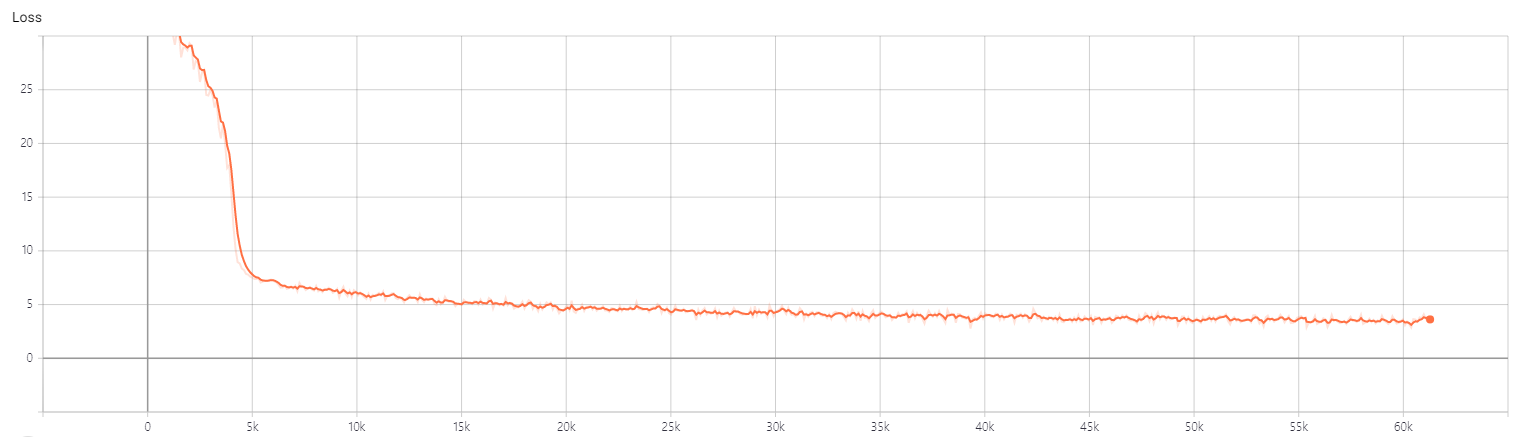
batch size는 32, dropout은 0.1, learning rate는 1e-4, epochs는 10으로 모델을 학습
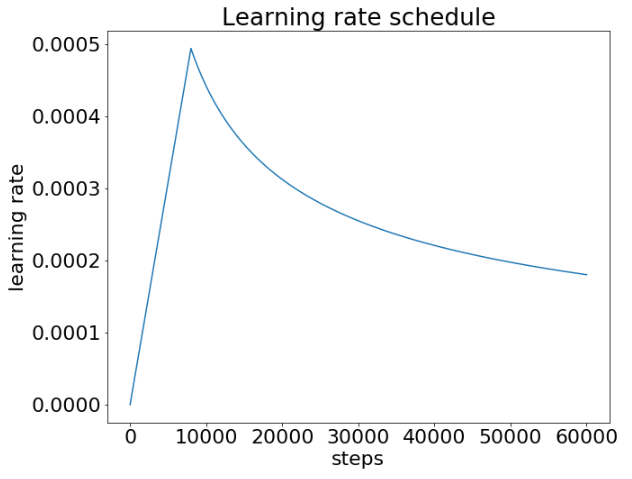
Learning rate schedule
Learning rate에 warm up과 Noam decay를 적용
Warm up step은 8000으로 지정
5. 결과
모델 검증
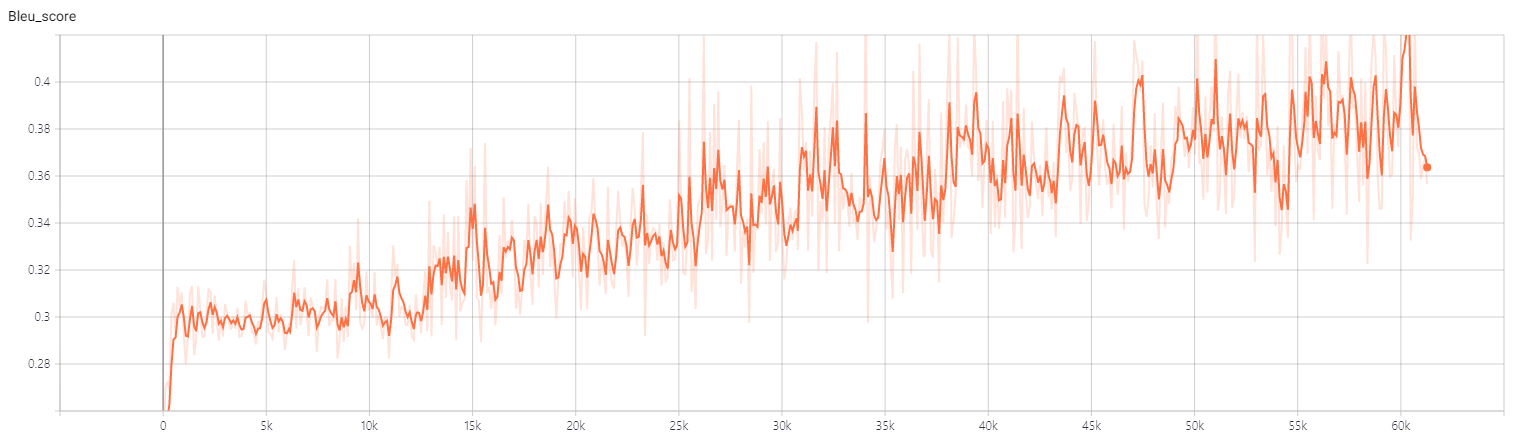
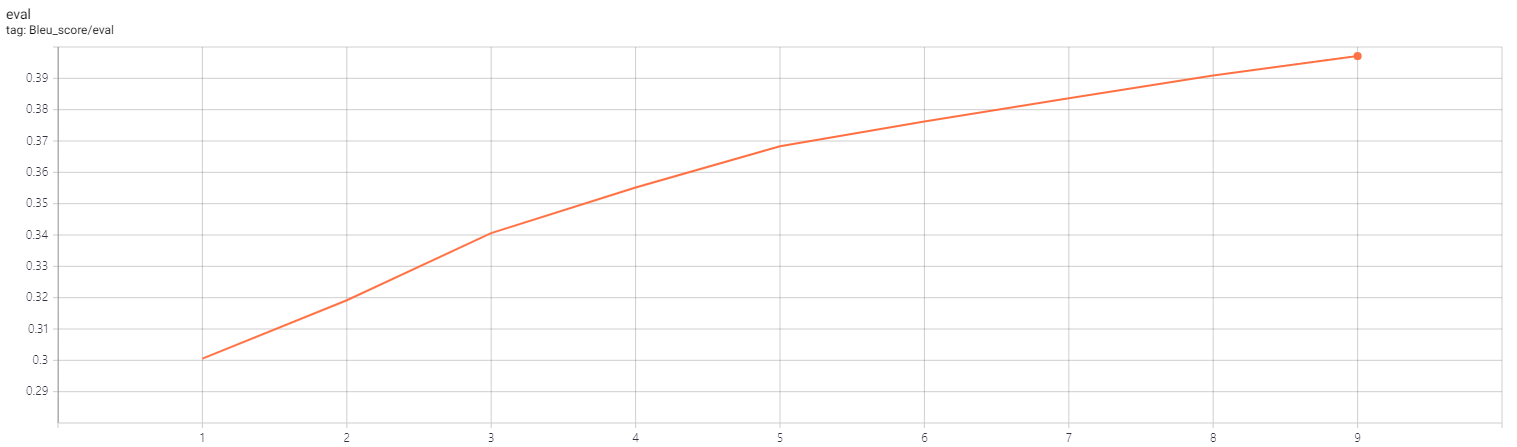
1천개의 테스트 데이터에 대해 약 0.39의 bleu score를 기록
Bleu score는 nltk에서 제공하는 bleu_score를 사용하고 smoothing을 적용
Leave a comment