
머신 러닝 분류 모델 평가
머신 러닝 모델을 만들었다면 그 모델을 사용하기 전에 성능을 평가해야 한다.
모델이 얼마나 실용적인지, 정밀한지, 그리고 정확하게 분류를 하는지 평가하는 기준이 필요하다.
분류 모델에서 많이 쓰이는 평가 방법인 Confusion Matrix를 소개하고자 한다.
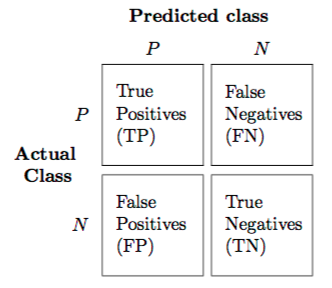
위 그림은 class가 2개인 이진 분류 모델의 confusion matrix이다.
Actual class는 실제 데이터의 라벨이고 Predicted class는 모델이 예측한 라벨이라고 볼 수 있다.
Positive인 class의 라벨을 1, Negative인 class의 라벨을 0 이라고 하자.
TP : 실제 라벨이 1인데 모델이 라벨을 1로 맞게 예측한 데이터의 수
FN : 실제 라벨이 1인데 모델이 라벨을 0으로 잘못 예측한 데이터의 수
FP : 실제 라벨이 0인데 모델이 라벨을 1로 잘못 예측한 데이터의 수
TN : 실제 라벨이 0인데 모델이 라벨을 0으로 맞게 예측한 데이터의 수
또한, 실제로 라벨이 1인 class의 수(P) = TP + FN, 라벨이 0인 class의 수(N) = FP + TN이라고 할 수 있다.
위의 confusion matrix를 사용해 여러 방법으로 모델의 성능을 평가할 수 있다.
Accuracy
대표적으로 많이 쓰이는 평가 지표이다.
모델이 얼마나 정확하게 예측을 했는지를 나타낸다.
\[Accuracy=\frac{TP + TN}{P + N}=\frac{모델이 맞게 예측한 데이터 수}{전체 데이터 수}\]Recall
Sensitivity 또는 TPR (True Positive Rate) 라고도 한다.
모델이 Positive인 class를 얼마나 잘 예측했는지를 나타낸다.
\[Recall=\frac{TP}{P}=\frac{TP}{TP + FN}=\frac{모델이 Positive로 맞게 예측한 데이터 수}{전체 Positive 데이터 수}\]Positive인 데이터들을 반드시 찾아내야 하는 모델인 경우 중요한 평가 지표가 될 수 있다.
Precision
모델이 Positive로 예측한 데이터가 얼마나 정확한지를 나타낸다.
\[Precision=\frac{TP}{TP + FP}=\frac{모델이 Positive로 맞게 예측한 데이터 수}{모델이 Positive로 예측한 데이터 수}\]Positive는 반드시 정확하게 예측해야 하는 모델인 경우 중요한 평가 지표가 될 수 있다.
Specificity
TNR (True Negative Rate)라고도 한다.
모델이 Negative인 class를 얼마나 잘 예측했는지를 나타낸다.
\[Specificity=\frac{TN}{N}=\frac{TN}{TN + FP}=\frac{모델이 Negative로 맞게 예측한 데이터 수}{전체 Negative 데이터 수}\]FPR (False Positive Rate)
실제로는 Negative이지만 Positive로 잘못 예측한 비율을 나타낸다.
\[FPR=\frac{FP}{N}=\frac{FP}{TN + FP}=\frac{모델이 Positive로잘못 예측한 데이터 수}{전체 Negative 데이터 수}\]평가 지표 선택
Accuracy 말고도 여러가지 평가 지표가 있다.
자신이 설계하는 모델의 목적에 맞는 평가 지표를 골라 모델의 성능을 평가해야 실제로 모델을 사용할 때 좋은 성능을 발휘할 수 있다.
또한, 특정 지표의 측정 값이 높다고 그 모델이 항상 좋은 성능을 발휘하는 것은 아니다.
예를들면, 어떠한 모델이 모든 데이터를 Positive라고 예측한다면 Recall 값은 100%의 값이 나올 것이다.
하지만 이 모델의 성능은 실제로 테스트하지 않아도 좋지 않을 것이라는 걸 알 수 있다.
예시를 하나 보자.
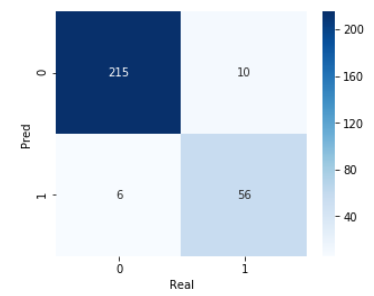
위의 matrix는 실제 라벨이 0인 데이터가 221개, 라벨이 1인 데이터가 66개로 총 287개의 데이터를 모델로 분류한 결과이다.
모델의 평가 지표로 accuracy를 사용한다면 94% 넘는 값을 얻을 수 있다.
‘94%의 accuracy를 얻었으니 어느정도 분류를 잘 하니 이 모델을 사용할 수 있겠다.’ 라고 생각하기 쉽다.
하지만 recall을 평가 지표로 사용한다면 84% 정도의 값 밖에 얻지 못한다.
만약, 위의 모델이 라벨이 1인 데이터들을 찾는 모델이었다면 좋은 성능을 기대하지 못할 것이다.
실제로 위의 모델은 필자가 웹 페이지를 분석해 content인 block과 non-content인 block을 분류하기 위해 만들었던 모델이다. (content의 라벨이 1, non-content의 라벨이 0이다.)
위의 모델을 사용해 웹 페이지를 분석한다면 어떤 결과가 나올까?
결과는 정말 좋지 않았다.
위의 matrix를 보면 실제로 라벨이 1인 데이터 수는 66개이고 모델이 예측한 라벨이 1인 데이터 수는 56개이다.
즉, 66개의 content block 중에서 56개만 찾아내고 나머지 10개의 block은 content가 아니라고 예측했다.
그 10개의 block 중에서 중요한 내용이 담겨 있는 block이 있다면 치명적인 결과를 만들 수도 있다.
Accuracy가 많이 사용되는 평가 지표이긴 하지만 accuracy를 무조건 신뢰해서는 안된다.
높은 accuracy를 얻었다고 해서 좋은 모델이라는 보장은 할 수 없다.
자신의 모델의 목적에 맞게 평가 지표를 선택하는 것이 필요하다.
Leave a comment