
ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
본 연구는 ERNIE: Enhanced Language Representation with Informative Entities의 후속 연구이다.
일반적으로 PLM들은 단어와 문장의 co-occurrence에 기반해 모델을 학습한다.
하지만, text에는 co-occurrence 외에도 lexical, syntactic, semantic한 정보들이 있다.
사람이나 지역의 이름같은 named entity는 conceptual한 정보를 갖고 있다.
문장의 순서 등의 정보는 모델이 structure-aware한 representation을 학습할 수 있게 한다.
또한, 문서 단위의 semantic similarity는 모델이 semantic-aware representation을 학습할 수 있게 한다.
본 연구에서는 이러한 다양한 task들을 continual multi task learning 방식으로 학습시킨다.
Continual multi task learning에서는 새로운 task를 받았을 때, 기존의 task와 같이 학습시킨다.
즉, 새로운 task를 학습시키면서 기존의 task에 대해 다시 학습시키게 된다.
이 때, task마다 encoding 모델은 공유한다.
The ERNIE 2.0 Framework
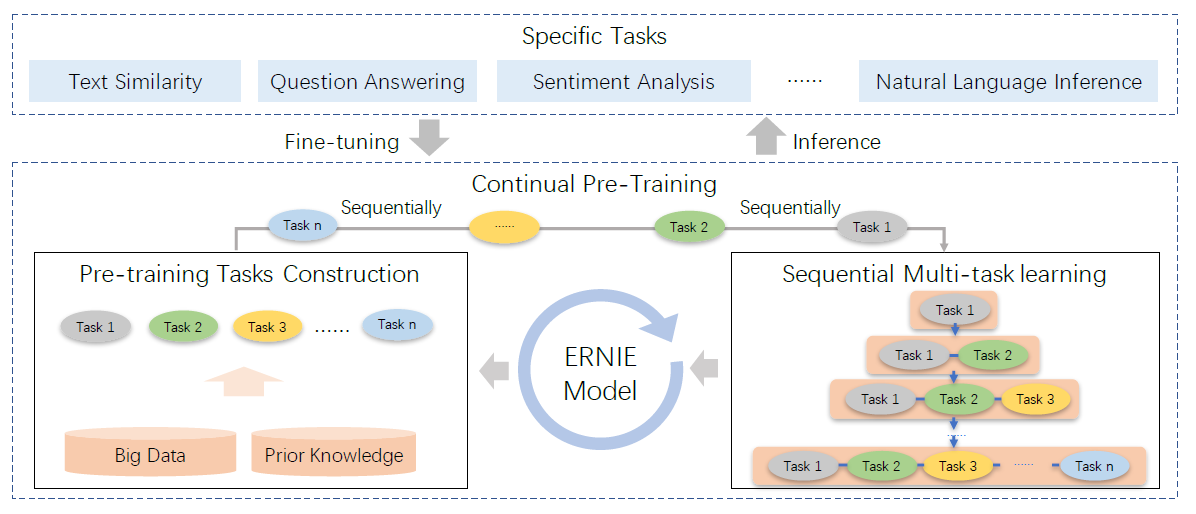
위의 그림은 ERNIE 2.0의 전체적인 구조를 보여준다.
기존의 pretraining들과는 다르게, 다양한 task들을 통해 lexical, syntactic, semantic한 representation을 학습시킨다.
Continual pretraining
Continual pretraining은 두 단계로 나뉜다.
- Prior knowledge와 많은 양의 데이터를 통해 계속해서 unsupervised pretraining task를 만든다.
- 점진적으로 multi task에 대해 모델을 학습시킨다.
Pretraining tasks construction
한번에 word-aware task, structure-aware task, 그리고 semantic-aware task를 만든다.
이 pretraining task들은 모두 거대한 데이터로부터 만들어지는 self-supervised 또는 weak-supervised 방식의 task이다.
Named entity, phrase, discourse relation 등의 prior knowledge를 사용해 거대한 데이터로부터 label을 생성한다.
Continual multi task learning
ERNIE 2.0은 다양한 task들을 통해서 lexical, syntactic, semantic한 information을 학습하는 것을 목표로 한다.
이를 위해서 두 가지 과제가 있다.
- 이전에 학습한 knowledge를 잊지 않고, 새로운 task들에 대해 계속해서 학습해야 한다.
- 이러한 task들을 효율적으로 pretraining 해야 한다.
이 두 가지를 해결하기 위해, 본 연구에서는 continual multi task learning을 제안한다.
새로운 task를 받으면, 먼저, 이전에 학습한 파라미터로 모델을 초기화시킨다.
그 후, 기존의 task들과 새로운 task에 대해서 같이 모델을 학습시킨다.
이를 통해, 학습된 모델이 이전의 knowledge들을 encoding 할 수 있다.
하지만, 여러 task들의 학습량을 같게 하기 위해서 각 단계별 iteration 수를 다르게 조절하여, task마다의 총 학습 iteration은 같게 설정한다.
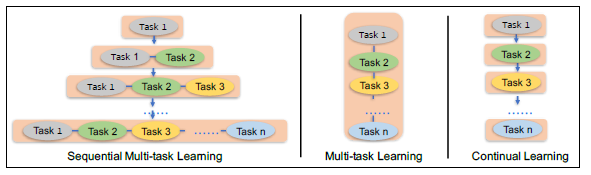
위의 그림은 3가지 learning 방법이 비교를 보여준다.
가운데는 일반적인 multi task learning이며, 여러 task를 한번에 같이 학습시킨다.
오른쪽은 continual learning이며, 여러개의 task를 여러 단계에 걸쳐 학습시킨다.
왼쪽이 본 연구에서 제안하는 방법으로, 단계가 지날수록 기존의 task들에 더해 새로운 task를 같이 학습시킨다.
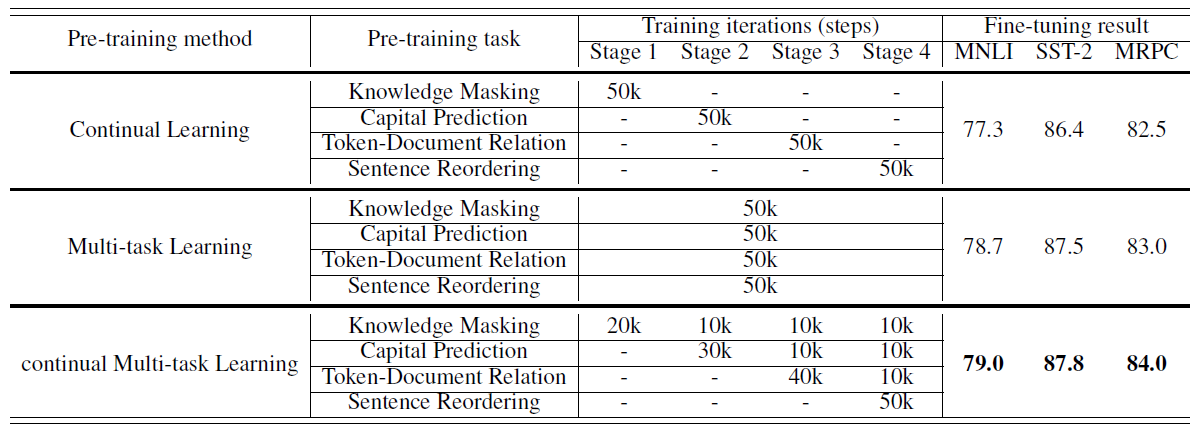
아래 표는 3가지 learning 방법의 결과를 보여준다.
아래 그림은 ERNIE 2.0이 여러 task들에서 encoding layer를 공유하는 모습을 보여준다.
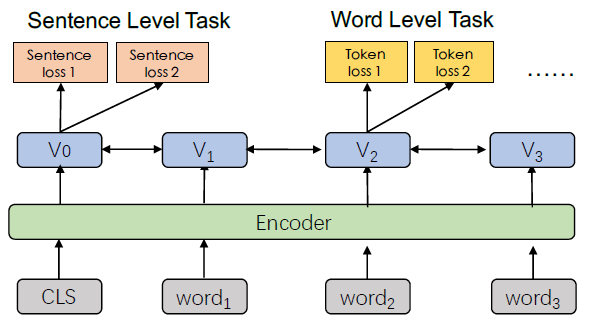
Encoder는 multi layer transformer를 의미한다.
BERT와 마찬가지로 [CLS] token의 output은 sequence 전체의 representation을 의미하며, token level의 loss는 각 token들마다 존재한다.
모델의 파라미터는 모든 task들에 대해서 학습되고, 각 pretraining task들은 각각의 loss를 가진다.
Finetuning for application tasks
Task specific한 supervised data들을 통해 finetuning함으로써, pretrain된 모델이 QA, NLI, semantic similarity 등의 여러 NLP task들에 적용될 수 있다.
각 downstream task들은 finetuning된 후에, 각각의 모델을 가진다.
ERNIE 2.0 Model
위에서 소개한 framework의 효율성을 보이기 위해, 본 연구에서는 3가지의 다른 유형의 unsupervised task들을 만들고 이 task들을 통해 ERNIE 2.0 모델을 만들었다.
Model structure
Transformer encoder
GPT, BERT, XLM 같은 기존의 PLM들과 마찬가지로 multi layer transformer를 encoder로 사용한다.
Transformer는 self attention을 통해서 각 token들의 contextual information을 학습할 수 있다.
Sequence의 가장 첫번째에 [CLS] token을 추가하며, 이 token의 output은 sequence 전체를 표현한다.
각 segment들 사이에는 [SEP] token이 추가되어 segment들을 구분한다.
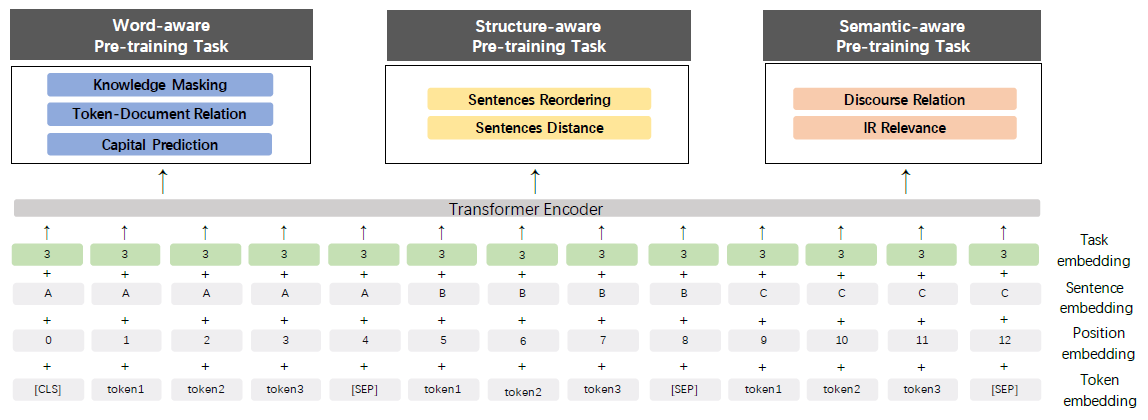
Task embedding
모델이 여러 task들의 특성을 학습하기 위해 task embedding을 추가한다.
각각의 task들을 0부터 N까지의 고유한 id로 표현한다.
이 id들은 모델에 의해 고유한 representation으로 학습된다.
모델의 input은 token, segment, position, task embedding을 모두 더해 사용한다.
Finetuning시에는 임의의 task id로 초기화한다.
아래 그림은 ERNIE 2.0의 embedding 방법을 보여준다.
Pretraining tasks
학습 데이터에서 각각 다른 관점의 정보들을 학습하기 위해 3가지의 다른 유형의 task들을 만들었다.
-
Word-aware task
모델이 lexical information을 학습한다.
-
Structure-aware task
모델이 syntactic information을 학습한다.
-
Semantic-aware task
모델이 semantic information을 학습한다.
Word-aware pretraining tasks
Knowledge masking task
[ERNIE 1.0]에서 knowledge를 통합하기 위한 방법으로 phrase masking과 named entity masking을 제안했다.
ERNIE 2.0에서도 이 방법을 사용하여 phrase와 named entity를 masking하고, 이를 예측하도록 모델을 학습한다.
이 task를 통해, 모델은 주어진 text 뿐 아니라 KB의 knowledge에도 의존적인 representation을 학습할 수 있다.
다시말해, local context와 global context에 모두 의존적인 정보를 학습할 수 있다.
Capitalization prediction task
일반적으로, 대문자로 쓰여진 단어들은 문장 안에서 다른 단어들에 비해 구체적인 semantic information을 갖고 있다.
Cased model, 즉, 대소문자를 구분하는 모델은 NER 같은 task에 효율적이며, uncased model은 다른 task들에 대해 효율적이다.
두 모델의 장점을 모두 사용하기 위해, 단어가 capitalized된 단어인지 아닌지를 구분하는 task로 모델을 학습시킨다.
Token-document relation prediction task
한 segment의 특정 token이 같은 document의 다른 segment에서도 등장하는지를 예측한다.
하나의 document에서 많이 등장하는 단어는 공통적으로 사용되는 단어거나 document의 topic과 관련이 있을 가능성이 많다.
즉, 이 task를 통해 모델은 token이 document에서 자주 등장하는지 아닌지를 식별함으로써 document의 key word를 파악하도록 학습된다.
Structure-aware pretraining tasks
Sentence reordering task
Pretraining 동안 주어진 paragraph을 무작위로 1부터 m개의 segment로 나누고 순서를 섞는다.
그 후, 원래의 순서를 예측하도록 모델을 학습시킨다.
즉, \(k=\sum_{n=1}^mn!\)에 대해 \(k\)-class의 classification task가 된다.
이 task를 통해 문장들간 relationship을 학습할 수 있다.
Sentence distance task
Document level의 정보를 사용해 문장들의 distance를 학습한다.
3-class classification task로 아래와 같이 분류한다.
- 두 문장이 같은 document에서 인접한 문장일 때, class를 0으로 분류한다.
- 두 문장이 같은 document에 존재하지만 인접하지 않을 때, class를 1로 분류한다.
- 두 문장이 다른 document에 존재할 때, class를 2로 분류한다.
Semantic-aware pretraining tasks
Discourse relation task
but, and, also 등의 두 sentence 사이의 discourse marker들을 예측하는 task이다.
본 연구에서 사용한 Mining Discourse Markers for Unsupervised Sentence Representation Learning 논문의 데이터는 174가지의 marker를 가지고 있기 때문에 174-class의 classification task가 된다.
이를 통해 두 문장 사이의 semantic relation을 학습할 수 있다.
IR relevance task
Information retrieval 상에서 짧은 text의 relevance를 학습한다.
Search engine의 데이터에서 query를 첫번째 sentence, title을 두번째 sentence로 입력받고 3-class classification을 수행한다.
- Title이 유저에 의해 클릭되었을 경우, strong relevance를 의미하며 class를 0으로 분류한다.
- Title이 search 결과에는 포함되었지만 유저가 클릭하지 않은 경우, weak relevance를 의미하며 class를 1로 분류한다.
- Title이 search 결과에 포함되지 않은 경우, irrelevance를 의미하며 class를 2로 분류한다.
이 task를 통해 문장간의 semantic한 relation을 학습할 수 있다.
논문 링크
Preprint 2019
ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
Leave a comment