
Improving Language Understanding by Generative Pre-Training(GPT)
Raw text를 효과적으로 학습하는 것은 NLP에 있어 supervised learning에 대한 의존을 줄일 수 있는 중요한 문제이다.
본 연구에서는 언어를 이해하기 위해 unsupervised pretraining과 supervised finetuning을 합친 semi supervised learning을 사용했다.
Transformer 모델을 학습시켰고, natural language inference, question answering, semantic similarity, text classification 총 4개의 task에서 평가를 진행했다.
Framework
Unsupervised pre-training
Corpus \(\LARGE u \normalsize =\{u_1,...,u_n \}\)가 주어졌을 때, 일반적인 language modeling을 사용해 다음과 같이 likelihood를 최대화시킨다.
\[L_1(\LARGE u\normalsize)=\sum_ilog\,P(u_i\mid u_{i-k},...,u_{i-1};\Theta)\]여기서, \(k\)는 window size이고 conditional probability \(P\)는 파라미터 \(\Theta\)로 modeling된 NN이다.
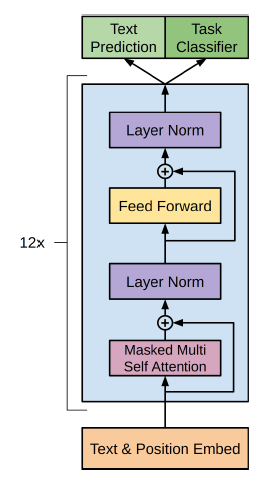
본 연구에서는 language model로 multi layer transformer decoder를 사용했으며 position wise feedforward layer에 multi head self attention을 적용시켜 target token의 distribution을 출력하는 모델을 만들었다.
\[h_0=UW_e+W_p\] \[h_l=transformer\_block(h_{l-1})\forall i\in[1,n]\] \[P(u)=softmax(h_nW_e^T)\]여기서 \(U=(u_k,...,u_1)\)는 token들의 context vector이고, \(n\)은 layer의 수, \(W_e\)는 token들의 embedding matrix 그리고 \(W_p\)는 position embedding matrix이다.
Supervised fine-tuning
Pretraining으로 학습한 파라미터를 supervised target task에 적용한다.
Labeled dataset을 \(C\)라고 할 때, 각 instance는 input token의 sequence \(x^1,...,x^m\)과 하나의 label \(y\)로 이루어져 있다.
입력된 sequence가 pretrain된 모델을 통과해 마지막 transformer block의 activation, \(h_l^m\)을 얻고, 이를 linear output layer에 입력해 아래와 같이 \(y\)를 예측한다.
\[P(y\mid x^1,...,x^m)=softmax(h_l^mW_y)\] \[L_2(C)=\sum_{(x,y)}log\,P(y\mid x^1,...,x^m)\]이와 같은 방법으로, supervised model의 일반화를 향상시킬 수 있고 convergence를 가속화시킬 수 있다.
구체적으로, 아래와 같은 목적 함수를 최적화시킨다.
\[L_3(C)=L_2(C)+\lambda L_1(C)\]Finetuning 과정에서 추가로 필요한 파라미터는 \(W_y\)와 delimiter toekn들의 embedding 뿐이다.
Task-specific input transformations
Text classification과 같은 몇몇 task들에서 위와 같이 finetuning 모델을 정의할 수 있다.
Question answering이나 textual entailment 같은 특정한 task들은 sentence의 pair, 질문과 답변 등 구조화된 input을 갖는다.
위의 모델은 연속된 sequence로 학습되기 때문에 이런 특정한 task들에서는 약간의 변화가 필요하다.
Transfer learning을 사용하기 보다는, 구조화된 input을 연속적인 sequence로 바꾸는 방법을 사용한다.
이러한 input transformation 방법은 task에 따라 모델의 구조가 많이 바뀌는 것을 방지할 수 있다.
아래 그림은 학습되는 transformer 구조와 finetuning 과정에서의 input transformation을 설명한다.
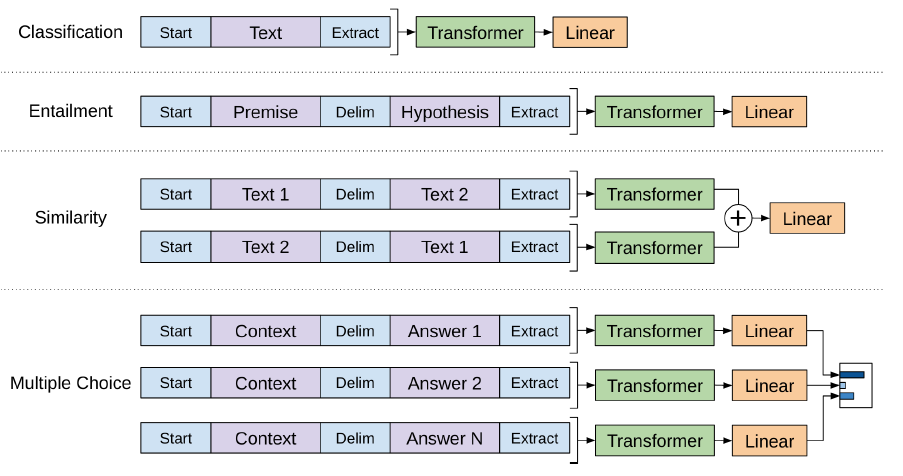
모든 transformation은 무작위로 초기화된 start \(<s>\)와 end \(<e>\) token을 추가로 갖는다.
Textual entailment
Entailment task에서는 premise \(p\)와 hypothesis \(h\)를 delimeter token \(\$\)로 연결한다.
Similarity
Similarity task에서는 두 sequence간 순서가 존재하지 않기 때문에 순서를 바꿔가며 두가지 경우를 모두 고려한다.
마찬가지로, \(\$\)로 연결하며 두 경우에서 각각 독립적으로 representation을 만든 후에 element wise로 더한 후에 linear output layer에 입력한다.
Question Answering and Commonsense Reasoning
이 task들에서는, context document \(z\), question \(q\) 그리고 가능한 answer들의 집합 \(\{a_k\}\)가 주어진다.
주어진 context document, question을 각각의 answer들과 연결해 \([z;q;$;a_k]\)의 형태를 만든다.
이렇게 만든 각각의 sequence들은 독립적으로 모델에 입력되어 처리된 후에 softmax layer를 통해 정규화된 분포를 출력한다.
Model specification
기본 transformer 구조를 비슷하게 사용한다.
12 layer의 decoder 스택만을 사용하며, 12개의 masked self attention head를 사용하고 hidden state의 size는 768로 설정했다.
Position wise feed forward network에서는 내부 hidden state의 size를 3072로 설정했다.
학습은 Adam optimizer를 사용했고 최대 learning rate는 2.5e-4로 설정했으며 learning rate는 0부터 시작해서 2000번 update된다.
입력 sequence의 token 길이는 512, batch size는 64로 설정하고 100 epoch 학습시켰다.
BPE 방식으로 40000번 merge해서 vocabulary를 만들었고 residual 구조를 사용했으며 attention dropout은 0.1로 설정했다.
Activation function으로는 GELU(Gaussian Error Linear Unit)을 사용했다.
기존 transformer와는 다르게 position embedding으로는 sinusoidal이 아닌 학습된 encoding을 사용했다.
또한, 공백과 punctuation은 정규화시켰다.
Leave a comment