
XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet은 GPT 같은 AutoRegressive(AR) 모델과 BERT 같은 AutoEncoder(AE) 모델의 장점을 합친 generalized AR pretraining 모델이다.
대부분의 NLP 테스트들에서 BERT를 큰 차이로 이기면서 state-of-the-art를 기록했다.
AutoRegressive(AR)
이전 시간(\(t-1\))의 결과가 현재 시간(\(t\))의 결과에 영향을 준다.
\[\Large X_t = c + \sum_{i=1}^p{\phi_iX_{t-i}}+\epsilon_t\] \[\Large \phi: parameter\] \[\Large \epsilon: white\:noise\]일반적인 Language Model과 마찬가지로 이전 token으로 다음 token을 예측하도록 학습된다.
대표적으로 ELMo, GPT가 있다.
AR은 한 방향의 정보만 이용하기 때문에 양방향의 문맥 정보를 이해하기 힘들다.
AutoEncoder(AE)
일반적으로 AE는 주어진 입력을 그대로 출력하도록 학습된다.
Denoising AE는 noise가 섞인 입력을 받고 원래의 입력을 예측하도록 학습된다.
BERT에서는 주어진 입력에 <MASK> token이라는 noise를 주고 <MASK> token을 원래 입력 token으로 예측하도록 학습된다.
AE는 AR과 다르게 양방향의 정보를 모두 활용할 수 있다.
하지만 <MASK> token은 모두 독립적으로 예측되기 때문에 이들 사이의 dependency를 학습할 수 없으며 실제 finetuning 과정에서는 <MASK> token이 등장하지 않기 때문에 pretraining과 finetuning의 불일치가 발생한다.
XLNet
용어
\(Z_T\): 가능한 모든 permutation의 집합
\(\Large z_t\): \(t\)번째 원소
\(\Large z_{<t}\): permutation \(\Large z\)의 \(t-1\)개의 원소들(\(\Large{z} \in Z_T\))
\(e(x)\): \(x\)의 embedding
\(\Large h_\theta (x_{z_{<t}})\): \(\Large x_{z_{<t}}\)가 NN을 통과해 나온 representation 값
\(\Large g_\theta(x_{z_{<t}},z_t)\): target position \(\Large z_t\)를 추가한 representation 값
Permutation Language Model
AR과 AE의 장점을 살리고 단점을 극복하기 위해 새로운 방법을 제안한다.
\[\large input: x=(x_1, x_2,...,x_T)\]일 때,
\[\Large max_\theta \: E_{z\sim Z_T}[\large \sum_{t=1}^T\Large log\,p_\theta (x_{z_t}|x_{z<t})]\]를 목적 함수로 사용해 모델을 학습한다.
input의 모든 permutation을 고려한 AR 방식을 사용한다.
파라미터 \(\theta\)는 학습 과정에서 모든 permutation에서 공유된다.
또한, input token \(x_t\)에 대해 input sequence안의 모든\(x_i(\not=x_t)\)들을 참조할 수 있기 때문에 양방향의 문맥을 학습할 수 있다.
원래 sequence는 보존된 상태에서 permutation의 순서만 바꾸며 원래 sequence에 맞게 적절한 positional encoding을 사용한다.
기존의 sequence는 보존하며 새로운 permutation sequence를 생성한다고 생각하면 될 것 같다.
Example
input이 \((x_1, x_2, x_3, x_4)\)라고 하면 permuntation의 집합은 \(4!=24\)개가 존재하며, \(Z_T=((1,2,3,4),(1,2,4,3),...,(4,3,2,1))\)이 된다.
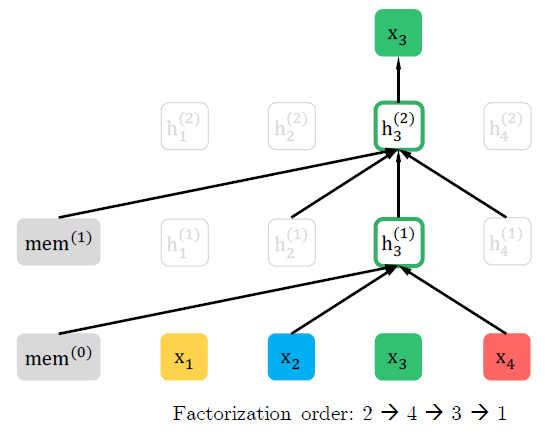
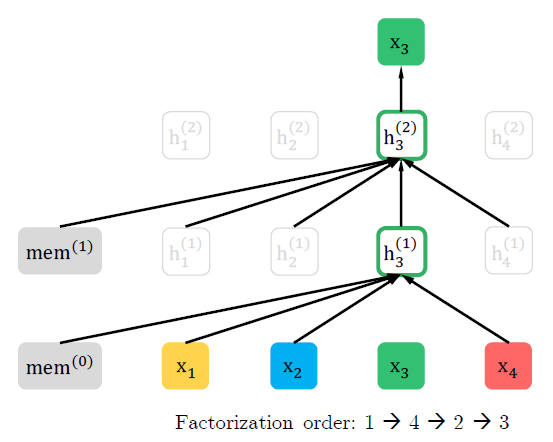
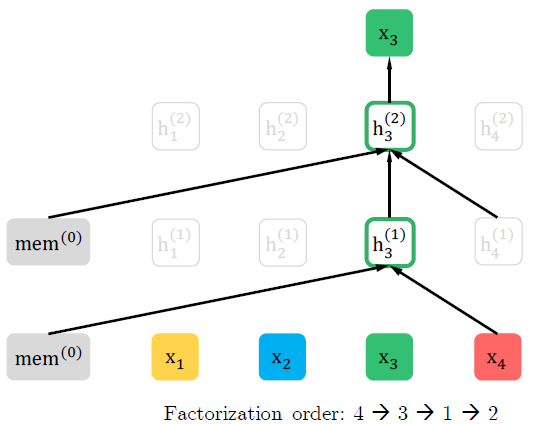
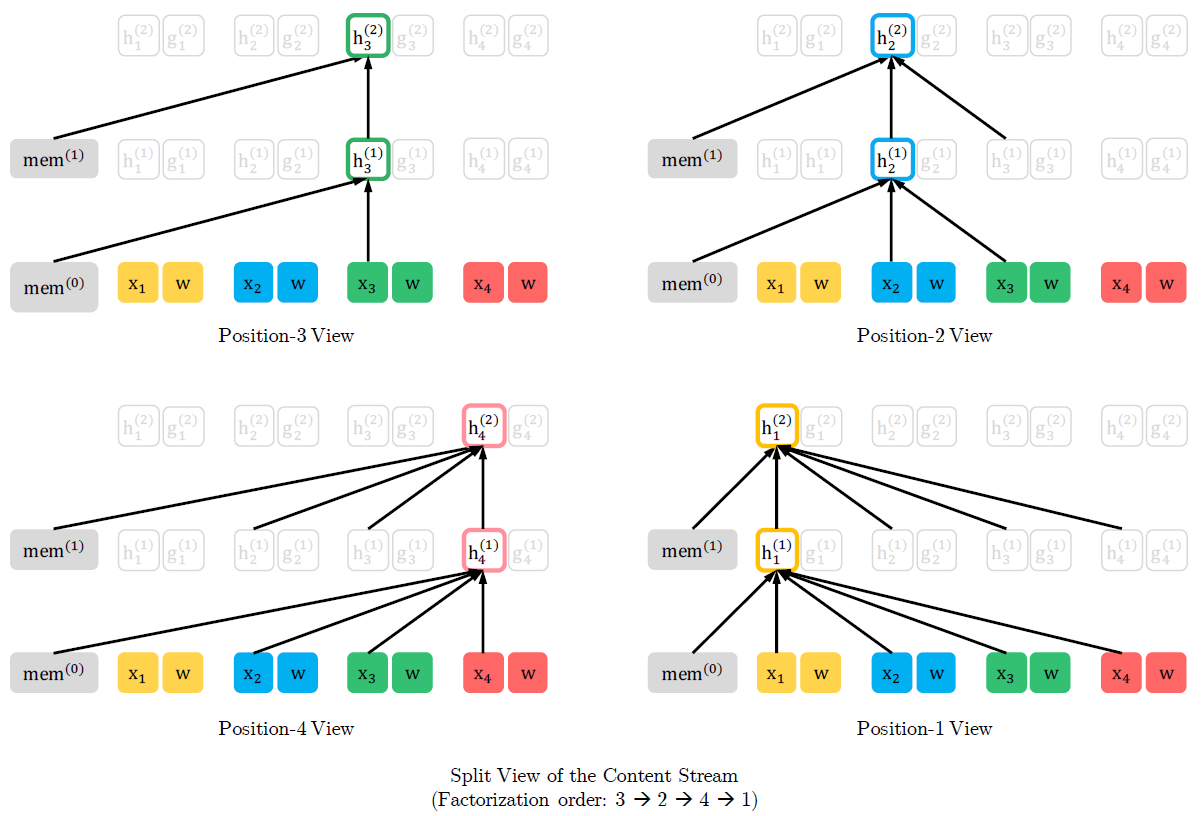
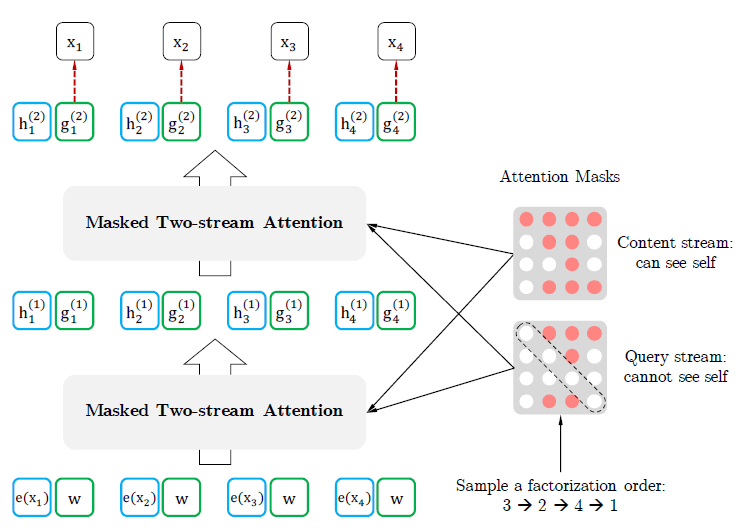
아래 그림은 다른 순서의 permutation이 같은 input을 예측할 때, 어떤 차이가 있는지를 보여준다.
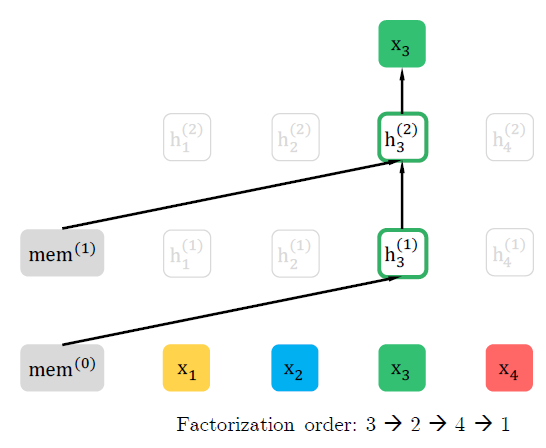
첫번째 그림에서는 \((3,2,4,1)\)의 순서이기 때문에 \(x_3\)이 다른 input의 영향을 받지 않는다.
두번째 그림에서는 \((2,4,3,1)\)의 순서이기 때문에 \(x_3\)이 \(x_2\)와 \(x_4\)의 영향을 받는다.
세번째, 네번째 그림도 두번째 그림과 같이 \(x_3\)이 다른 input의 영향을 받는다.
모든 permutation에 대해 같은 과정을 수행하면, \(x_3\)을 제외한 \((x_1,x_2,x_4)\)의 모든 부분집합에 대한 \(x_3\)의 conditional probability를 계산할 수 있다.
즉, 특정 token에 대해서 양방향의 정보를 사용한 AR 모델을 만들 수 있다.
또한 <MASK> token을 사용하지 않기 때문에 pretraining과 finetuning 사이의 불일치도 발생하지 않는다.
Two-Stream Self-Attention for Target-Aware Representations
Softmax를 사용해 다음 token을 예측한다고 하면, 아래와 같은 식을 얻을 수 있다.
\[\Large p_\theta(X_{z_t}=x|x_{z_{<t}})=\frac{exp(e(x)^Th_\theta(x_{z_{<t}}))}{\sum_{x'}exp(e(x')^Th_\theta(x_{z_{<t}}))}\]하지만, \(\Large h_{\theta}(x_{z_{<t}})\)는 target position에 관계 없이 값을 예측하기 때문에 적절한 representation을 학습할 수 없다.
예를 들어, \(Z_T=((1,2,3,4),(1,2,4,3),...,(4,3,2,1))\) 라고 하면
- \((1,2,3,4)\)의 경우, \(p(x_3\mid x_1,x_2)\)를 계산하려면 \(h_{\theta}(x_1,x_2)\)을 사용한다.
- \((1,2,4,3)\)의 경우, \(p(x_4\mid x_1,x_2)\)를 계산하려면 \(h_{\theta}(x_1,x_2)\)을 사용한다.
즉, 같은 representation 값을 사용해 \(x_3\)과 \(x_4\)를 예측하게 된다.
이런 문제를 해결하기 위해 \(\Large g_{\theta}(x_{z_{<t}},z_t)\)라는 target position, \(\Large z_t\)를 input으로 하는 새로운 representation을 사용한다.
마찬가지로 softmax를 적용해서 다음 token을 예측한다고 하면, 아래와 같은 식을 얻을 수 있다.
\[\Large p_\theta(X_{z_t}=x\mid x_{z_{<t}})=\frac{exp(e(x)^Tg_\theta(x_{z_{<t}},z_t))}{\sum_{x'}exp(e(x')^Tg_\theta(x_{z_{<t}},z_t))}\]이로써 Target position에 관한 문제는 해결할 수 있지만, \(\Large g_{\theta}(x_{z_{<t}},z_t)\)를 수식으로 만드는 문제가 남아있다.
일반적인 transformer 구조와는 다르게 다음의 2가지 조건을 만족해야 한다.
- token \(\Large x_{z_t}\)를 예측하기 위해 \(\Large g_{\theta}(x_{z_{<t}},z_t)\)는 \(\Large x_{z_t}\)가 아닌 position \(z_t\)만을 이용해야한다.
- \(j>t\)인 token들 \(\Large x_{z_j}\)를 예측하기 위해 \(\Large g_{\theta}(x_{z_{<t}},z_t)\)는 \(\Large x_{z_t}\)를 encoding 해야한다.
하지만, 위의 2가지 조건을 모두 만족할 수는 없다.
그렇기 때문에 본 연구에서는 2개의 representation stream을 사용한다.
또한 각각의 self attention layer \(m=1,...,M\) 에서 2개의 representation stream은 파라미터를 공유하며 학습된다.
Content representation stream
Content representation \(\Large h_{\theta}(x_{z_{\leq t}})\)는 일반적인 transformer와 비슷한 역할을 수행한다.
문맥 정보와 \(\Large x_{z_t}\) 그 자체를 모두 encoding 한다.
첫번째 layer에서는 word embedding 값을 사용한다.
\[\Large h_i^{(0)}=e(x_i)\] \[\Large h_{z_t}^{(m)} \leftarrow Attention(Q=h_{z_t}^{(m-1)},KV=h_{z_{\leq t}}^{(m-1)};\theta)\]Content representation은 일반적인 self attention과 똑같은 방식으로 학습된다.
그렇기 때문에 finetuning 과정에서 query stream을 없애고 content stream을 일반적인 transformer처럼 사용할 수 있다.
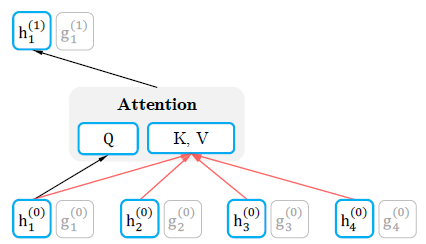
아래 그림은 Content stream의 전체적인 흐름이다.
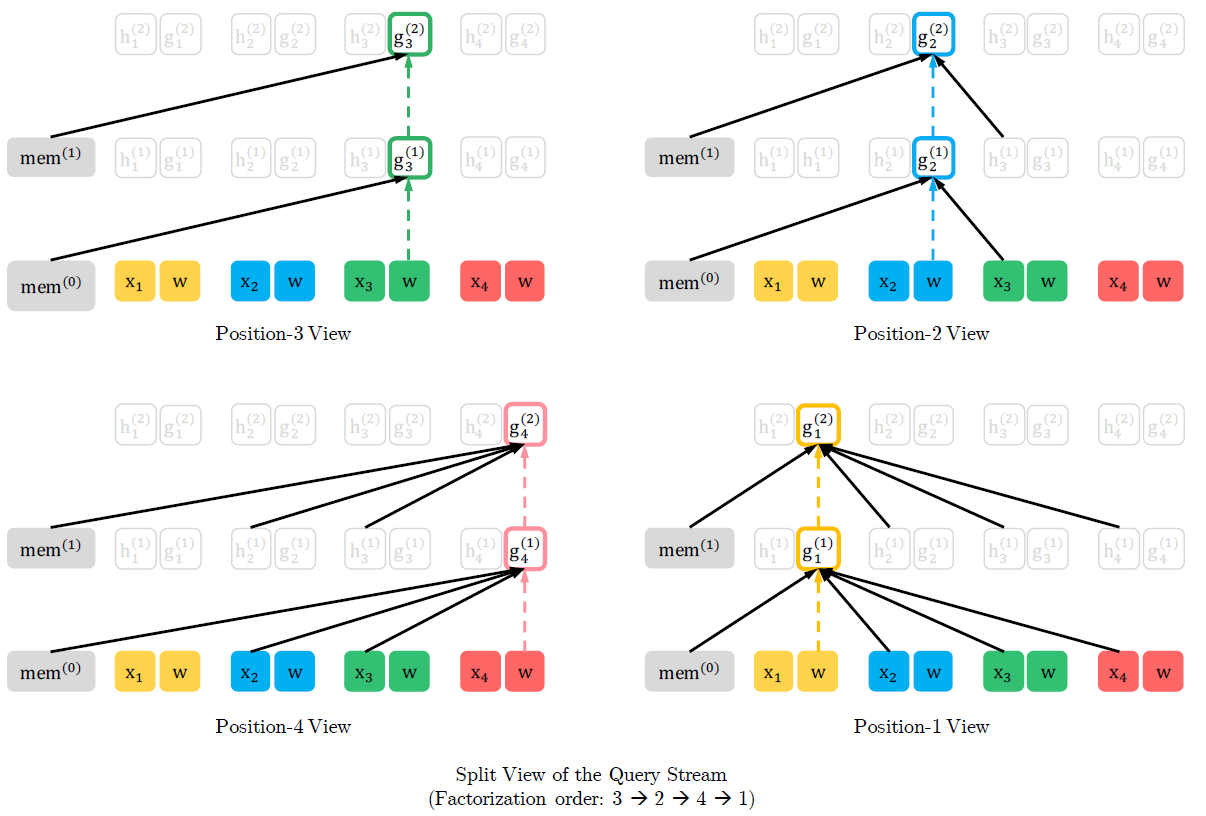
Query representation stream
Query representation \(\Large g_{\theta}(x_{z_{<t}},z_t)\)는 문맥 정보 \(\Large x_{z_{<t}}\)와 position \(\Large z_t\)만을 사용한다.
\(\Large x_{z_t}\)는 사용하지 않는다.
첫번째 layer에서는 학습되는 vector로 초기화한다.
\[\Large g_i^{(0)}=w\] \[\Large g_{z_t}^{(m)} \leftarrow Attention(Q=g_{z_t}^{(m-1)},KV=h_{z_{<t}}^{(m-1)};\theta)\]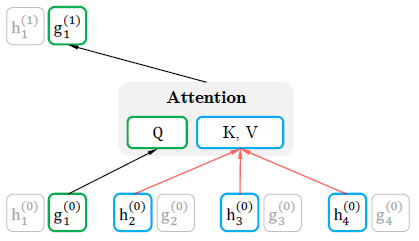
위의 그림에서 \(\Large g_1^{(0)}\)은 \(x_1\)의 position 정보를 가지고 있다고 볼 수 있다.
마지막 layer의 query representation \(\Large g_{z_t}^{(M)}\)을 \(\Large p_\theta(X_{z_t}=x\mid x_{z_{<t}})\)를 구하는 데에 사용할 수 있다.
아래 그림은 Query stream의 전체적인 흐름이다.
Partial prediction
Permutation Language Model은 많은 장점이 있지만 optimization 과정에 있어 어려움이 있고 속도가 느리다.
이런 단점을 해결하기 위해 본 연구에서는 하나의 permutation에서 마지막 token들만을 예측했다.
Permutation \(\Large z\)를 non-target subsequence인 \(\Large z_{\leq c}\)와 target sequence인 \(\Large z_{>c}\)로 나눈다.
즉, non-target subsequence가 주어졌을 때, target subsequence의 log-likelihood를 최대화 하는 것을 목적으로 한다.
\[\Large max_\theta \:E_{z\sim Z_T}[log\,p_\theta(x_{z_{>c}}\mid x_{z_{\leq c}})]=E_{z\sim Z_T}[\sum_{t=c+1}^{\mid z\mid }log\,p_\theta(x_{z_t}\mid x_{z_{<t}})]\]여기서 hyperparameter \(K\)를 선택하고, \(\Large \frac{1}{K}\)개의 token을 예측한다. 즉, \(K\approx\Large \frac{\mid z\mid }{\mid z\mid -c}\)
Incorporating Ideas from Transformer-XL
본 연구에서는 Transformer-XL의 2가지 중요한 기술을 통합시킨다.
- Relative positional encoding scheme
- Segment recurrence mechanism
기존 sequence에 대한 relative positional encoding은 앞서 기술했다.
Permutation 기법에 recurrence mechanism을 통합시키고 모델이 이전 segment의 hidden state를 재사용할 수 있게 만드는 방법을 소개한다.
긴 sequence \(s\)로 부터 2개의 segment \(x, \tilde{x}\)를 만들었다고 가정한다.
\[\Large \tilde{x}=s_{1:T},\:x=s_{T+1:2T}\] \[\Large \tilde{z}=(1,...,T),\:z=(T+1,...,2T)\]Permutation \(\tilde{z}\)에 대해 첫번째 segment를 처리하고 얻은 각 layer \(m\)의 representation \(\Large \tilde{h}^{(m)}\)을 caching 한다.
그 후, 다음 segment \(x\)에서 아래와 같이 attention을 update한다.
\[\Large h_{z_t}^{(m)}\leftarrow Attention(Q=h_{z_t}^{(m-1)},KV=concat(\tilde{h}^{(m-1)},h_{z_{\leq t}}^{(m-1)});\theta)\]Positional encoding은 기존의 seqeunce에만 의존하기 때문에 한번 \(\Large \tilde{h}^{(m)}\)을 계산하면 위의 update는\(\tilde{z}\)에 독립적이다.
즉, 이전 segment의 permutation를 알 필요 없이 정보를 재사용할 수 있다.
이를 통해 모델은 이전 segment의 모든 permutation에서 정보를 학습할 수 있다.
Query stream 역시 같은 방법으로 학습된다.
아래 그림은 two-stream attention으로 학습되는 Permutation Language Model을 간략하게 나타낸 것이다.
Modeling Multiple Segments
질의응답 같은 많은 downstream 문제들은 몇개의 input segment들을 갖는다.
AR 방식으로 multiple segments를 모델링하기 위해 XLNet을 어떻게 pretrain 하는지를 다룬다.
BERT 처럼, 무작위로 2개의 segment들을 선택한다. 즉, segment들은 같은 문맥에서 선택될 수도 있고 서로 다른 문맥에서 선택될 수도 있다.
그 후, 2개의 segment를 concat해서 하나의 sequence로 만든다.
같은 문맥의 정보들은 재사용한다.
모델에 입력되는 형태는 BERT와 비슷하게 [A, SEP, B, SEP, CLS] 이다.
Two-segment의 데이터 형태를 따르지만, 다음 문장을 예측하는 것은 지속적인 성능 향상을 보장하지 않아 XLNet-Large 모델은 이를 목적으로 하지 않는다.
Relative Segment Encodings
각 position의 word embedding에서 absolute segment embedding을 사용하는 BERT와는 다르게, 본 연구에서는 Transformet-XL로 부터 relative encoding 방식을 확장시켰다.
Position \(i, j\) 쌍이 주어졌다고 할 때, 아래와 같이 \(\Large s_{ij}\)를 정의한다.
- \(i,j\)가 같은 segment에 속한 경우, \(\Large s_{ij}=s_+\)
- \(i,j\)가 같은 segment에 속하지 않은 경우, \(\Large s_{ij}=s_-\)
여기서 \(\Large s_+\)와 \(\Large s_-\)는 각각의 attention head에서 학습되는 파라미터이다.
즉, 두 position이 같은 segment 인지, 아닌지만 고려한다.
\(\Large s_{ij}\)는 attention weight \(\Large a_{ij}=(q_i+b)^Ts_{ij}\)를 계산할 때 사용된다.
여기서, \(\Large q_i\)는 일반적인 attention에서의 query vector이며 \(\Large b\)는 학습되는 bias이다.
Relative segment encoding의 장점은 2가지가 있다.
- Inductive한 bias로 인해 일반화가 잘 이루어진다.
- 2개 이상의 input segment를 갖는 finetuning 문제에 대한 가능성을 열었다.
Comparison with BERT
BERT와 XLNet은 둘다 partial prediction을 수행한다. 즉, sequence 전체가 아닌 token들의 subset만을 예측한다.
BERT에서는 모든 token들을 masking하면 의미있는 예측이 불가능하기 때문에 필요한 기술이다.
또한, partial prediction은 최적화 과정의 어려움을 감소시켜준다.
하지만 BERT에서는 masking된 token, 즉, target들 사이의 dependency를 모델링할 수 없다.
예를 들어, [New, York, is, a, city]라는 sequence에서 BERT와 XLNet 모두 [New, York]을 target으로 선택했다고 하면 \(log\,p(New\:York\mid is\:a\:city)\)를 최대화하도록 학습된다.
또한, XLNet은 permutation의 순서를 (is, a, city, New, York)으로 선택했다고 하면 아래와 같은 목적 함수를 정의할 수 있다.
다시말해, XLNet은 두 target New와 York의 dependency를 학습할 수 있다.
Comparison with Language Modeling
GPT 같은 AR language model의 경우는 한 방향의 dependency만 학습할 수 있다.
위의 예시에서 York을 예측할 때 New를 사용할 수 있지만 New를 예측할 때는 York을 사용할 수 없다.
하지만, XLNet은 모든 경우의 permutation을 고려하기 때문에 양방향의 dependency를 학습할 수 있다.
다른 예를 들면, "Thom Yorke is the singer of Radiohead"라는 문맥에서 "Who is the singer of Radiohead"라는 질문에 대한 답을 할 때, AR language model은 "Thom Yorke"의"Radiohead"에 대한 dependency를 표현할 수 없다.
Pretraining & Implementation
BERT에서 사용했던 BooksCorpus 데이터와 English Wikipedia 데이터에 추가적으로 Giga5, ClueWeb 2012-B, Common Crawl 데이터를 사용해 pretraining을 진행했다.
Sentence Piece를 사용해 tokenization을 진행했다.
Recurrence 구조가 소개되었기 때문에 양방향의 데이터 입력 파이프라인을 사용해 , forward와 backward 방향이 각각 batch size의 절반을 처리한다.
XLNet-Large 모델을 학습시키는 과정에서 파라미터 \(K\)는 6으로 설정했다.
Finetuning 과정에서는 span-based prediction 방법을 사용했다.
길이 \(L\in[1,2,3,4,5]\)을 선택하고 무작위로 연속적인 \(L\)개의 token span을 target으로 선택해 예측한다.
논문 링크
Preprint 2019
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Leave a comment