
BERT with History Answer Embedding for Conversational Question Answering
전통적인 AI들은 크게 3가지 유형으로 분류된다.
- Task-oriented bot
- Social bot
- Question Answering bot
Siri 같은 개인 비서들은 많은 연구가 진행되어 왔지만 복잡한 multi-turn의 대화는 잘 다루지 못한다.
복잡한 대화에서 시스템이 사용자의 요구를 제대로 이해하기 이해서는 대화의 history를 다룰 수 있어야 한다.
본 연구에서는 BERT 기반의 Conversational Question Answering 모델이 conversation history를 통합할 수 있게 한다.
Conversation history를 MC(Machine Comprehension) 모델에 통합시키는 것에는 2가지 관점이 있다.
-
History selection
다른 history 보다 도움이 될 것이라고 판단되는 집합을 선택한다.
-
History modeling
선택된 history를 MC 모델로 만든다.
기존에 연구되었던 방법들은 아래와 같은 방법들이 있다.
- 단순하게 history turn을 추가하는 방법
- 대화에서 answer를 mark하는 방법
- 복잡한 attention을 사용하는 방법
첫번째와 두번째 방법은 긴 대화를 잘 다루지 못하는 문제가 있었고 세번째 방법은 복잡한 구조로 인해 많은 오버헤드가 발생하는 문제가 있었다.
문제 정의
Passage \(p\), \(k\)번째 질문 \(q_k\) 그리고 \(q_k\) 앞의 conversation history \(H_k\)가 주어졌을 때,
\(q_k\)에 대한 대답, \(a_k\)를 예측해 질문 \(q_k\)에 대한 대답을 하는 것을 문제로 정의한다.
\(H_k\)는 \(k-1\)개의 대화 turn을 가지고 있다. 여기서, \(H_k^i=(q_i,a_i)\)
Conversational Question Answering Framework
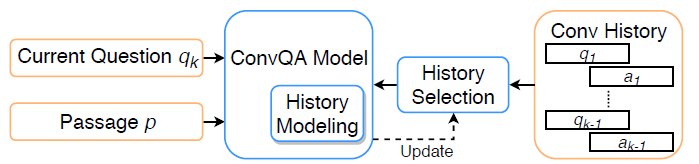
Framework는 크게 3 부분으로 나뉜다.
- Conversational QA 모델
- History selection 모듈
- History modeling 모듈
실질적으로 History modeling 모듈은 ConvQA 모델 내부의 메커니즘이 될 수 있다.
학습 인스턴스(\(p,q_k,H_k,a_k\))가 주어졌을 때, History selection 모듈은 history turn들의 부분집합인 \(H'_k\)를 선택한다.
그 후에, History modeling 모듈이 \(H'_k\)를 ConvQA 모델에 통합시킨다.
History selection 모듈이 잘 학습되어 있는 상태라면, ConvQA 모델은 자기 자신을 제대로 업데이트 할 수 있다.
본 연구에서는 가까운 history turn들이 현재 질문에 더 연관이 있을 것이라 가정하고, rule-based 방식으로 \(j\)번째 이전의 turn을 선택한다.
Machine Comprehension
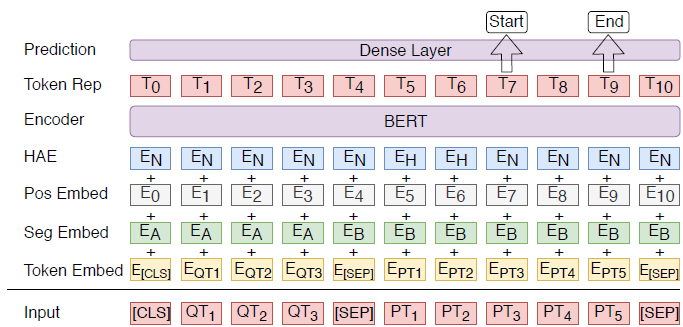
BERT를 기반으로 한 MC 모델이다.
Input은 질문과 passage이고, output은 passage의 각 토큰들이 대답의 start/end가 될 확률이다.
start/end vector는 해당 토큰이 대답의 start/end 토큰인지의 확률을 계산하도록 학습된다.
\(T_i\)는 \(i\)번째 토큰을 BERT로 표현한 것이고 \(S\)는 start vector이다.
여기서 토큰이 start 토큰이 될 확률 \(\Large P_i=\frac{e^S\cdot T_i}{\sum_j{e^S\cdot T_j}}\) 이다.
각 토큰이 end 토큰이 될 확률도 같은 방법으로 계산하며 loss는 start와 end 위치의 각각 cross entropy의 평균으로 계산한다.
History Answer Embedding
ConvQA 모델의 MC 모델과의 중요한 차이는 conversation history를 다루는 것이다.
History selection 모듈이 선택한 history turn을 모델로 만들어야 한다.
본 연구에서는 토큰에 추가적으로 embedding된 정보를 줌으로써 conversation history를 모델화한다.
BERT의 3가지 embedding에 더해서 HAE layer를 추가해 history를 embedding한다.
각 토큰들이 history에 포함되는지(\(E_H\)) 아닌지(\(E_N\))를 embedding해서 input에 더해준다.
BERT는 문맥적인 정보를 고려하기 때문에 하나의 토큰에 HAE를 추가하는 것은 그 토큰에만 영향을 주는 것이 아니라 seqeuence 전체에 영향을 준다.
모델 학습
학습 인스턴스(\(p,q_k,H_k,a_k\))가 주어졌을 때, 먼저 그것을 (\(p,q_k,H_k^i,a_k\))의 리스트로 변환한다.
여기서, 리스트의 각 원소는 conversation history의 하나의 turn만 포함한다.
History selection 모듈은 \(j\) 이전의 turn을 선택하고 그 turn을 merge해서 새로운 인스턴스(\(p,q_k,H'_k,a_k\))를 만든다.
새로운 인스턴스를 ConvQA 모델의 input을 만드는데에 사용한다. 여기서, \(H_k'\)는 HAE에 사용된다.
긴 passage를 나누기 위해 sliding window 방식을 사용한다.
데이터
본 연구에서는 QuAC(Question Answering in Context) 데이터 셋을 사용해 실험을 진행했다.
이 데이터 셋은 정보를 요구하는 쪽(seeker)과 정보를 제공하는 쪽(provider)의 대화를 포함하고 있다.
Seeker는 질문을 통해 Wikipedia의 passage들을 학습하기는 것을 목적으로 한다.
Provider는 질문에 대한 대답으로써 passage의 짧은 부분을 제공한다.
많은 질문들은 conversation history에 대한 참조를 갖는다.
학습/검증 데이터는 각각 11K/1K 개의 대화들과 83K/7K 개의 질문들로 이루어져 있다.
모든 대화 데이터는 12 turn 이내에 끝난다. 즉, 질문은 최대 11개의 history turn을 가질 수 있다.
QuAC example

STUDENT는 Wikipedia의 passage를 알지 못하고 Section만 아는 상태에서 질문을 한다.
TEACHER는 Wikipedia의 passage에 접근할 수 있어 질문에 대한 답을 준다.
답이 불가능한 경우에는 No answer로 대답한다.
논문 링크
SIGIR 2019
BERT with History Answer Embedding for Conversational Question Answering
Leave a comment