
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT(Bidirectional Encoder Representations from Transformer)
BERT는 크게 pre training과 fine tuning 부분으로 나뉜다.
그림으로 표현하면 아래와 같다.
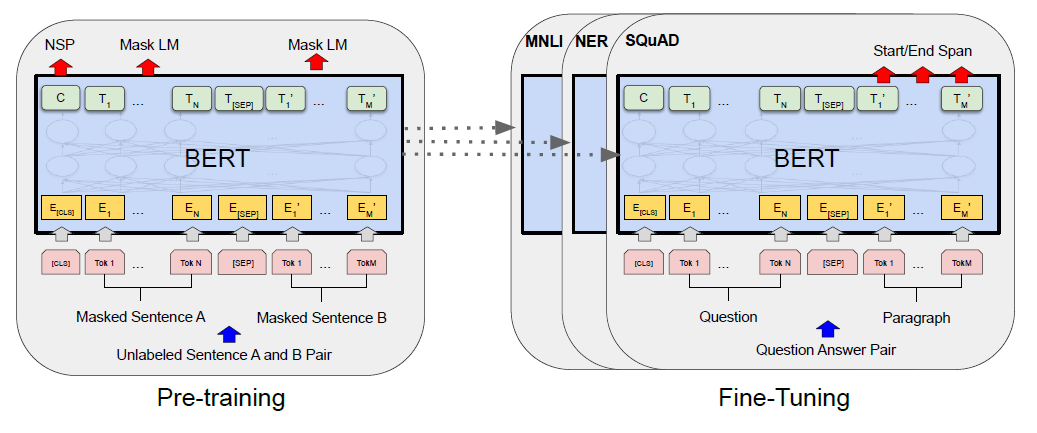
Pre-training
양방향의 context를 통해 label이 없는 text를 표현하기 위해 pre-train된다.
Pre-training 과정은 거대한 unlabeled 데이터를 사용해 이루어진다.
본 논문에서는 BookCorpus(800M words)와 Wikipedia(2500M words) 데이터를 사용해 모델을 학습했다.
또한, 연속적인 sequence의 관계를 학습하기 위해 document 단위의 corpus를 사용해 학습했다고 설명하고 있다.
Pre-training 과정에서는 다음과 같은 방법으로 학습을 진행한다.
-
Masked Language Model
input sequence의 token들을 랜덤으로 masking하고 그 token을 예측하도록 모델을 학습시킨다.(bidirectional)
-
Next Sentence Prediction
다음 sentence를 예측하도록 학습한다.
학습 방법의 자세한 설명은 아래에서 기술한다.
Fine-tuning
Pre-training 과정에서 학습시킨 모델을 label이 있는 데이터로 재학습시킨다.
Pre-train된 BERT는 단순히 언어를 표현하기 위한 모델일 뿐 분류, 예측 등의 기능은 가지고 있지 않다.
따라서 원하는 task에 맞게 새로운 데이터를 사용해 모든 파라미터를 fine-tuning하는 과정이 필요하다.
Pre-train된 BERT 모델에 추가적인 layer를 쌓고 모델을 fine-tuning함으로써 감성 분류, 질의 응답 등의 모델을 만들 수 있다.
아래 그림은 다양한 task에 대해 BERT를 학습시키는 그림이다.
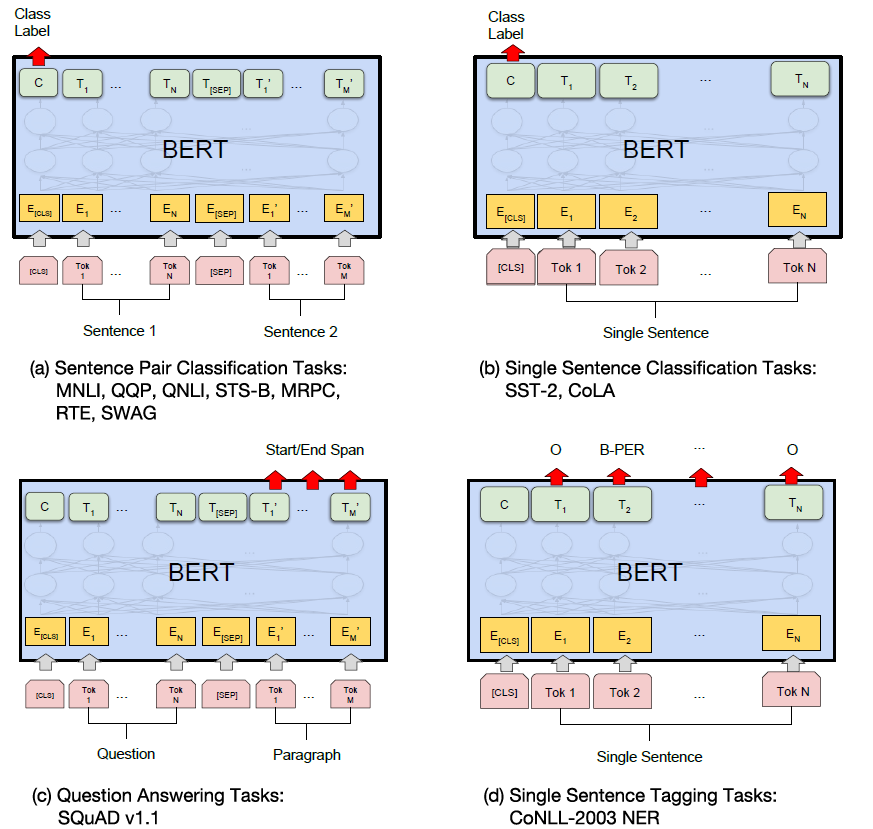
Model Architecture
BERT 모델은 multi layer bidirectional Transformer encoder 라고 논문에 소개된다.
쉽게 말하면 Transformer 모델의 encoder 부분을 기반으로 한다고 할 수 있다.
논문에서는 \(BERT_{BASE}\)와 \(BERT_{LARGE}\) 두가지 버전의 모델을 소개한다.
\(BERT_{BASE}\)
Layer의 수, \(L=12\)
Hidden layer의 크기, \(H=768\)
Self attention head의 수, \(A=12\)
총 parameter의 수\(=110M\)
성능 비교를 위해 OpenAI의 GPT 모델과 같은 크기로 만들어진 버전이다.
\(BERT_{LARGE}\)
Layer의 수, \(L=24\)
Hidden layer의 크기, \(H=1024\)
Self attention head의 수, \(A=16\)
총 parameter의 수\(=340M\)
더 큰 모델로, State Of The Art를 기록한 버전이다.
Input/Output
하나의 sentence와 sentence의 pair(question & answer) 모두 하나의 token의 sequence로 만들 수 있어야 한다.
하나의 sentence를 하나의 sequence로 만드는 것은 단순하게 sentence를 여러 token으로 나누면 되므로 문제가 없다.
하지만 sentence의 pair를 하나의 sequence로 만들기 위해서는 각 sentence를 구분해 줄 필요가 있다.
그렇기 때문에 BERT 모델에서는 <SEP> token을 사용한다.
두 sentence 사이에 <SEP> token을 추가해 sentence를 구분할 수 있다.
또한, 각 sequence의 처음은 <CLS> token을 사용한다.
<CLS> token은 classification을 위해 사용되는 token이다.
Sequence의 embedding은 Word Piece Model을 사용하고 token vocabulary의 크기는 30,000이다.
Sequence를 embedding할 때, 단순히 token을 embedding해서 모델에 입력하는 것이 아니라 추가로 두 가지의 embedding을 한다.
-
Segment embedding
두 sentence A, B를 하나의 sequence로 embedding할 때,
<SEP>token으로 두 sentence를 구분해주는 것 뿐 아니라 각 token들이 A와 B중 어떤 sentence에 속하는지를 학습시킨 embedding을 token embedding 값에 더해준다. -
Position embedding
BERT 역시 Transformer 모델과 마찬가지로 recurrent나 convolution 구조를 사용하지 않기 때문에 위치 정보를 추가할 필요가 있다.
이를 해결하기 위해 각 token의 position을 학습시킨 position embedding을 token embedding 값에 더해준다.
BERT의 입력 sequence의 embedding을 그림으로 표현하면 아래와 같다.
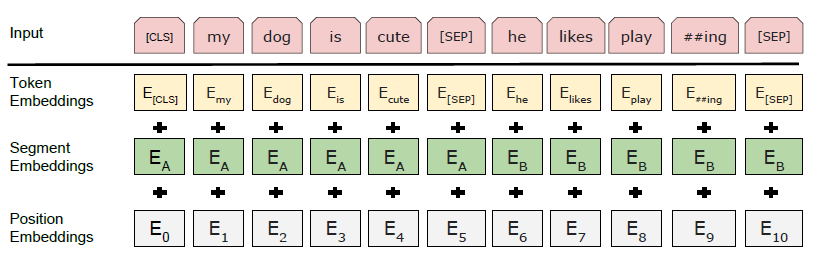
BERT는 output으로 각 position마다 hidden layer의 크기, \(H\)와 같은 크기의 vector를 출력한다.
그림으로 간단하게 아래와 같이 표현할 수 있다.
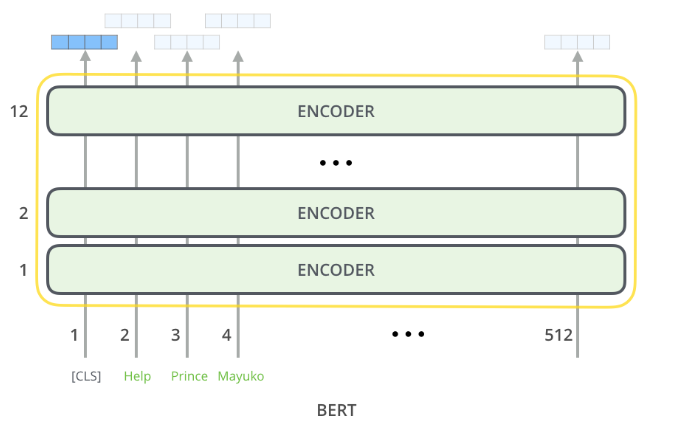
BERT를 사용해 classification 문제를 해결하고자 한다면 아래와 같이 사용할 수 있다.
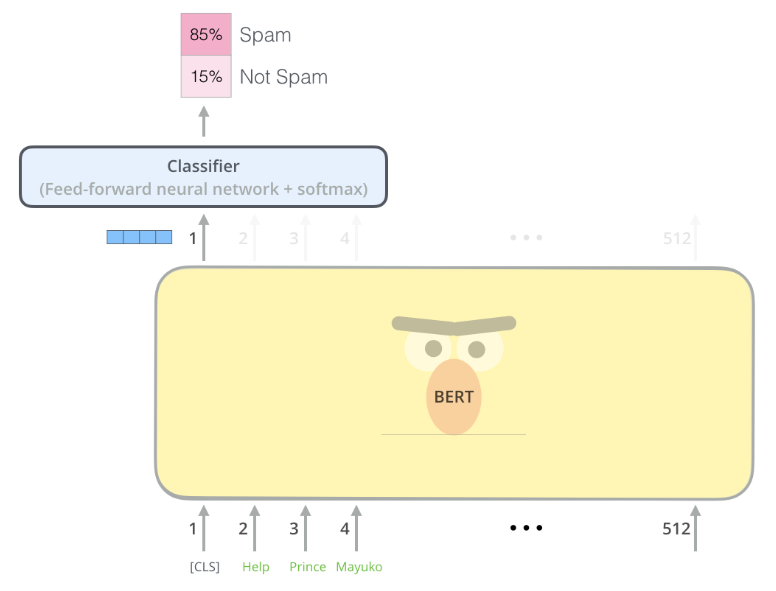
<CLS> token에 해당하는 output이 classification을 위해 추가된 Feed forward network의 입력으로 들어가고 softmax를 통해 classification을 수행한다.
Word Piece Model(WPM)
본 논문에 자세하게 소개된 내용은 아니지만 BERT 모델에 있어 중요한 기술이므로 소개하고자 한다.
단어를 embedding하는 하나의 방법이다.
단어 embedding 기술로 유명한 Word2Vec 같은 경우는 하나의 단어를 단위로 해서 embedding한다.
하지만, 이러한 방법은 vocabulary의 크기가 커질 수 밖에 없고 OOV 문제도 자주 발생하는 문제점이 있다.
이러한 단점을 보완하기 위해 단어를 더 작게 나누는 방법을 사용한다.
WPM은 자주 등장하는 단어는 그 자체로 하나의 token으로 사용하며 자주 등장하지 않는 단어는 sub word로 나눠서 각각의 sub word들을 token으로 사용한다.
Jet makers feud over seat width big orders at stake
위의 문장에 WPM을 적용하면 아래와 같이 나눌 수 있다.
_J et _makers _fe ud _over _seat _width _big _orders _at _stake
WPM은 다음과 같은 특징을 가진다.
- 모든 단어의 앞에는 ‘_‘를 붙인다.
- 새로 만들어진 sub word의 앞에는 ‘_‘를 추가로 붙이지 않는다.
- 모든 token들을 concat하고 ‘_‘를 공백으로 치환하면 원래 문장을 복원할 수 있다.
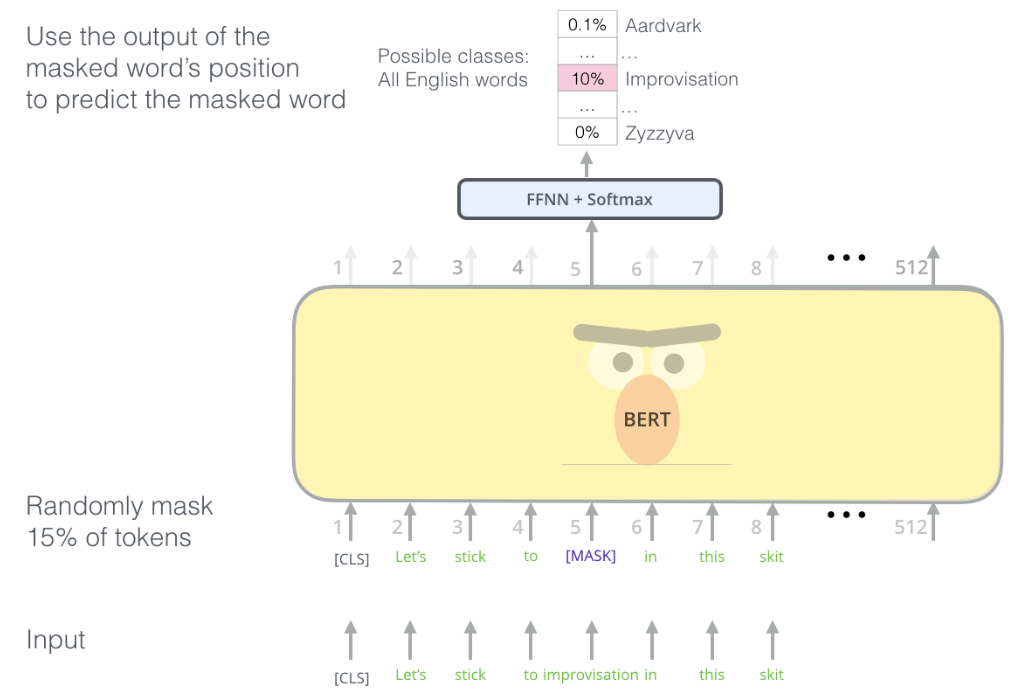
Masked Language Model(MLM)
일반적인 Language Model과는 다르게 bidirectional 하게 모델을 학습시킨다.
무작위로 몇 개의 token들을 masking한 후에 그 token들을 예측하도록 학습시킨다.(논문에서는 15%를 masking한다고 기술했다.)
하지만 이러한 학습은 pre-training 과정에서만 이루어지고 fine-tuning 과정에서는 <MASK> token이 존재하지 않기 때문에 문제가 발생할 수 있다.
이를 해결하기 위해 masking 되는 token을 모두 <MASK> token으로 바꾸는 것이 아니라 80%는 <MASK> token으로 바꾸고, 10%는 다른 무작위 token으로 바꾸며, 10%는 바꾸지 않고 그대로 유지한다.
이러한 과정을 거치고 해당 position의 output으로 원래 token을 예측하도록 학습한다.
학습에는 cross entropy를 사용한다.
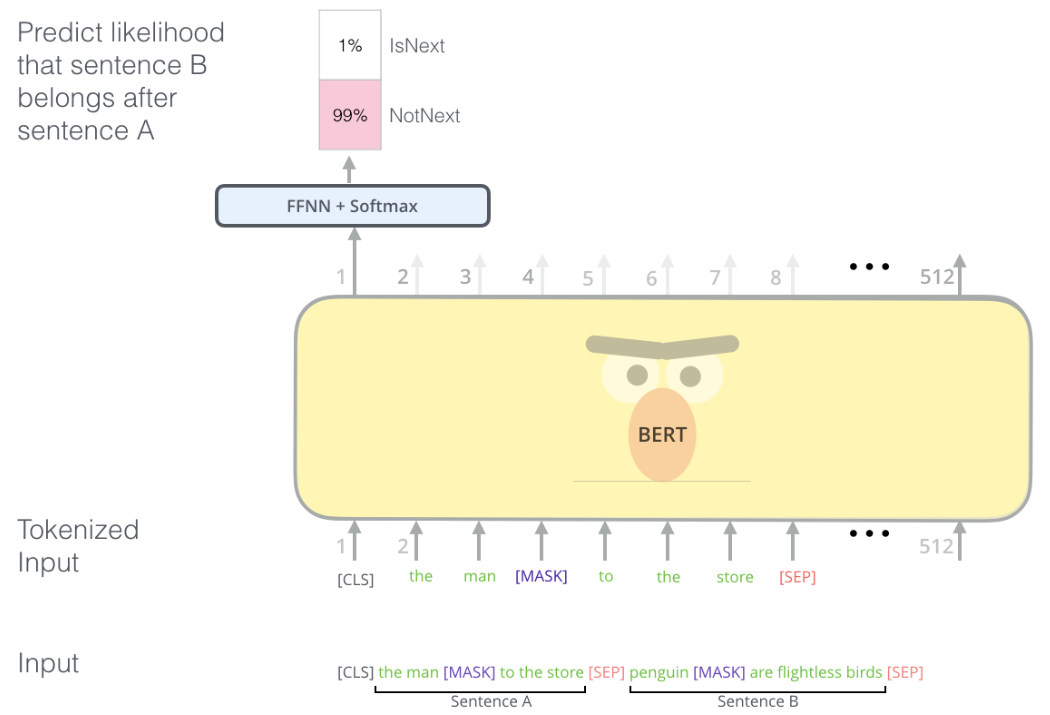
Next Sentence Prediction(NSP)
질의 응답 등의 문제를 해결하기 위해서는 두 sentence 사이의 관계를 잘 학습해야 한다.
하지만 단순한 Language model로는 제대로 학습이 힘들다.
BERT는 이러한 문제를 해결하기 위해 pre-training 과정에서 모델이 다음 sentence를 예측하도록 학습시켰다.
두 sentence A, B를 하나의 sequence로 입력할 때, 50%는 B에 A의 진짜 다음 sentence를 할당하고 50%는 무작위 sentence를 할당한다.
여기서, B가 A의 다음 sentence인 경우에는 label을 “IsNext”로 설정하고 아닌 경우에는 “NotNext”로 설정한다.
다시말하면, 다음 sentence를 예측하는 문제를 <CLS> token에 해당하는 output을 사용해 binary classification 문제로 학습시킨다.
논문 링크
NAACL 2019
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Leave a comment